Шпаргалка на тему Лекции по информатике
Работа добавлена на сайт bukvasha.net: 2015-06-29Поможем написать учебную работу
Если у вас возникли сложности с курсовой, контрольной, дипломной, рефератом, отчетом по практике, научно-исследовательской и любой другой работой - мы готовы помочь.

Предоплата всего

Подписываем
Введение в проблему искусственного интеллекта (ИИ) Понятие систем ИИ, их классификация области применения и перспективы развития. Использование систем ИИ в организационном управлении. 1. Понятие систем ИИ, их классификация области применения и перспективы развития. ИИ - это научно-исследовательское направление создающие модели и соответствующие программные средства, позволяющие с помощью ЭВМ решать задачи творческого, не вычислительного характера, которые в процессе решения требуют обращения к семантике (проблеме смысла). Исследования в области ИИ проводятся в течение 30 лет.
Началом работ в области ИИ считают создание ЭВМ, которая должна была имитировать процесс человеческого мышления. Разработка Розенблата. Машина-персептрон имела два вида нейтронов, которые образовывали нейтронную сеь. Исследования в области ИИ разделились на два подхода: 1)Конекционистский 2)Символьный Начало работ в (2) считают разработки университета Корнеги Меллона, а именно два программных комплекса: а)логик-теорик; б)общий решатель задач. В конце 60-х изменилась методология решения задач ИИ, т.е. вместо моделирования способов мышления человека началась разработка программ способных решать человеческие задачи, но на базе Эффективных машинно-ориентированных методов. Исследовательским полигоном этого периода явились головоломки и игры. Это объясняется замкнутостью пространства поиска решений и возможностью моделирования очень сложной стратегии поиска решения. В то же время делаются попытки перенести ИИ из искусственной среды в реальную. Возникает проблема моделирования внешнего мира. Это привело к появлению интегральных роботов, которые изначально должны были выполнять определенные операции в технологических процессах, работать в опасных для человека средах. С появлением роботов большое внимание уделяется реализации функции формирования действий, восприятие ими информации о внешней среде. Появление роботов считают вторым этапом исследований в ИИ. В начале 70-х акценты в ИИ сместились на создание человеко-машинных систем, позволяющих комплексно на основе эвристических методов вырабатывать решения в рамках конкретных предметных областей на основе символьного подхода. В это же время стали развиваться бурными темпами экспертные системы (ЭС). ЭС - позволяет выявлять, накапливать и корректировать знания из различных областей и на основе этих знаний формировать решения , которые считаются если не оптимальными, то достаточно эффективными в определенных ситуациях. ЭС используют знания группы экспертов в рамках определенной предметной области. В качестве экспертов используются конкретные специалисты, которые могут быть не достаточно знакомы с ЭВМ. В настоящее время в общем объеме доля ЭС составляет до 90%. Если проранжировать области применения по количеству созданных образцов: Медицинская диагностика, обучение, консультирование. Проектирование ЭС. Оказание помощи пользователям по решению задач в разных областях. Автоматическое программирование. Проверка и анализ качества ПО. Проектирование сверхбольших интегральных схем. Техническая диагностика и выработка рекомендаций по ремонту оборудования. Планирование в различных предметных областях и анализ данных, в том числе и на основе статистических методов. Интерпретация геологических данных и выработка рекомендаций по обнаружению полезных ископаемых. Первые образцы ЭС занимали по трудоемкости разработки 20-30 человеко/лет. В коллектив разработчиков входили: эксперты предметной области, инженеры по знаниям или проектировщики ЭС, программисты. В проектировании ЭС есть существенное отличие от проектирования традиционных информационных систем. Это объясняется тем, что в ЭС используется понятие “знание”, а в традиционной системе - “данные”. В ЭС отсутствует понятие жесткого алгоритма, а всевозможные действия задаются в виде правил, которые являются эвристиками, т.е. эмпирическими правилами или упрощениями. В процессе работы системы производится построение динамического плана решения задачи с помощью специального аппарата логического вывода понятий. С появлением ЭС появилась новая научная дисциплина - инженерия знаний, которая занимается исследованиями в области представления и формализации знаний, их обработки и использования в ЭС. В настоящее время под термин ЭС попадает очень большой круг систем, которые можно отнести к ЭС только по используемым моделям и методам проектирования. Поэтому делается попытка более строгой классификации систем ИИ символьного направления.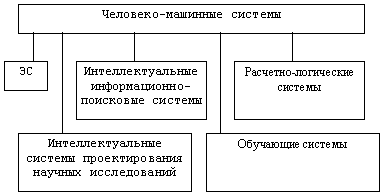 В настоящее время при широком использовании символьного подхода усилилось внимание к использованию нейтронных сетей. Это объясняется тем, что предложены очень мощные модели нейтронных сетей и алгоритмы их обучения (метод обратного распространения ошибок). Нейтронные сети используются в медицинской диагностике, управлении самолетом, налоговых и почтовых службах США. Одной из составляющих успеха нейтронных сетей явилась совместная разработка компании Intel и корпорации Nestor микросхемы с архитектурой нейтронных сетей. Тенденции развития средств вычислительной техники: Развитие вычислительной базы: параллельные, нейтронные и оптические технологии, которые будут способны к распределенному представлению информации, параллельной ее обработки, обучению и самоорганизации. Развитие теоретической основы для информационной обработки основанный на понятии ‘Softlogic’, поддерживающий как логический, так и интуитивный вывод понятий. Разработка для реальных приложений системы когнетивных функций, таких как речь, звуковые эффекты, когнетивная графика и т.п. ЭС как разновидность систем ИИ. Структура ЭС. Определение знаний и базы знаний (БЗ). Определение понятий логического вывода. Организация интерфейса с пользователем в ЭС. 1. Структура ЭС.
В настоящее время при широком использовании символьного подхода усилилось внимание к использованию нейтронных сетей. Это объясняется тем, что предложены очень мощные модели нейтронных сетей и алгоритмы их обучения (метод обратного распространения ошибок). Нейтронные сети используются в медицинской диагностике, управлении самолетом, налоговых и почтовых службах США. Одной из составляющих успеха нейтронных сетей явилась совместная разработка компании Intel и корпорации Nestor микросхемы с архитектурой нейтронных сетей. Тенденции развития средств вычислительной техники: Развитие вычислительной базы: параллельные, нейтронные и оптические технологии, которые будут способны к распределенному представлению информации, параллельной ее обработки, обучению и самоорганизации. Развитие теоретической основы для информационной обработки основанный на понятии ‘Softlogic’, поддерживающий как логический, так и интуитивный вывод понятий. Разработка для реальных приложений системы когнетивных функций, таких как речь, звуковые эффекты, когнетивная графика и т.п. ЭС как разновидность систем ИИ. Структура ЭС. Определение знаний и базы знаний (БЗ). Определение понятий логического вывода. Организация интерфейса с пользователем в ЭС. 1. Структура ЭС. 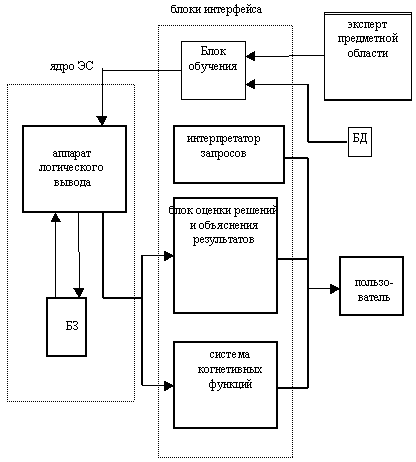 2. Определение знаний и базы знаний (БЗ). Основным элементом БЗ являются знания о предметной области, в которой должна функционировать ЭС. Знание - это совокупность сведений, образующих целостное описание соответствующее определенному уровню осведомленности об описываемой проблеме. Основное отличие знаний от данных в том, что данные описывают лишь конкретное состояние объектов или группы объектов в текущий момент времени, а знания кроме данных содержат сведения о том как оперировать этими данными. В БЗ ЭС знания должны быть обязательно структурированы и описаны терминами одной из модели знаний. Выбор модели знаний - это наиболее сложный вопрос в проектировании ЭС, так как формальное описание знаний оказывает существенное влияние на конечные характеристики и свойства ЭС. В рамках одной БЗ все знания должны быть однородно описаны и простыми для понимания. Однородность описания диктуется тем, что в рамках ЭС должна быть разработана единая процедура логического вывода, которая манипулирует знаниями на основе стандартных типовых подходов. Простота понимания определяется необходимостью постоянных контактов с экспертами предметной области, которые не обладают достаточными знаниями в компьютерной технике. Знания подразделяются с точки зрения семантики на факты и эвристики. Факты как правило указывают на устоявшиеся в рамках предметной области обстоятельства, а эвристики основываются на интуиции и опыте экспертов предметной области. По степени обобщенности описания знания подразделяются на: Поверхностные - описывают совокупности причинно- следственных отношений между отдельными понятиями предметной области. Глубинные - относят абстракции, аналогии, образцы, которые отображают глубину понимания всех процессов происходящих в предметной области. Введение в базу глубинных представлений позволяет сделать систему более гибкой и адаптивной, так как глубинные знания являются результатом обобщения проектировщиком или экспертом первичных примитивных понятий. По степени отражения явлений знания подразделяются на: Жесткие - позволяют получить однозначные четкие рекомендации при задании начальных условий. Мягкие - допускают множественные расплывчатые решения и многовариантные рекомендации. Тенденции развития ЭС.
2. Определение знаний и базы знаний (БЗ). Основным элементом БЗ являются знания о предметной области, в которой должна функционировать ЭС. Знание - это совокупность сведений, образующих целостное описание соответствующее определенному уровню осведомленности об описываемой проблеме. Основное отличие знаний от данных в том, что данные описывают лишь конкретное состояние объектов или группы объектов в текущий момент времени, а знания кроме данных содержат сведения о том как оперировать этими данными. В БЗ ЭС знания должны быть обязательно структурированы и описаны терминами одной из модели знаний. Выбор модели знаний - это наиболее сложный вопрос в проектировании ЭС, так как формальное описание знаний оказывает существенное влияние на конечные характеристики и свойства ЭС. В рамках одной БЗ все знания должны быть однородно описаны и простыми для понимания. Однородность описания диктуется тем, что в рамках ЭС должна быть разработана единая процедура логического вывода, которая манипулирует знаниями на основе стандартных типовых подходов. Простота понимания определяется необходимостью постоянных контактов с экспертами предметной области, которые не обладают достаточными знаниями в компьютерной технике. Знания подразделяются с точки зрения семантики на факты и эвристики. Факты как правило указывают на устоявшиеся в рамках предметной области обстоятельства, а эвристики основываются на интуиции и опыте экспертов предметной области. По степени обобщенности описания знания подразделяются на: Поверхностные - описывают совокупности причинно- следственных отношений между отдельными понятиями предметной области. Глубинные - относят абстракции, аналогии, образцы, которые отображают глубину понимания всех процессов происходящих в предметной области. Введение в базу глубинных представлений позволяет сделать систему более гибкой и адаптивной, так как глубинные знания являются результатом обобщения проектировщиком или экспертом первичных примитивных понятий. По степени отражения явлений знания подразделяются на: Жесткие - позволяют получить однозначные четкие рекомендации при задании начальных условий. Мягкие - допускают множественные расплывчатые решения и многовариантные рекомендации. Тенденции развития ЭС. 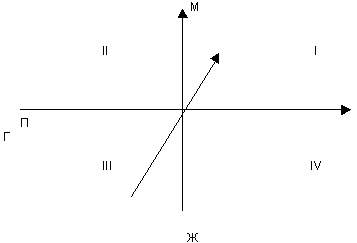 М,Ж - мягкие, жесткие знания. П,Г - поверхностные, глубинные знания. медицина, управление психодиагностика, планирование диагностика неисправностей разного вида проектирование различных видов устройств Обычно при проектировании БЗ проектировщик старается пользоваться стандартной моделью знаний (МЗ): продукционная модель знаний (системы продукции) логическая МЗ фреймовая МЗ реляционная МЗ По форме описания знания подразделяются на: Декларативные (факты) - это знания вида “А есть А”. Процедурные - это знания вида “Если А, то В”. Декларативные знания подразделяются на объекты, классы объектов и отношения. Объект - это факт, который задается своим значением. Класс объектов - это имя, под которым объединяется конкретная совокупность объектов-фактов. Отношения - определяют связи между классами объектов и отдельными объектами, возникшие в рамках предметной области. К процедурным знаниям относят совокупности правил, которые показывают, как вывести новые отличительные особенности классов или отношения для объектов. В правилах используются все виды декларативных знаний, а также логические связки. При обработке правил следует отметить рекурсивность анализа отношений, т.е. одно правило вызывает глубинный поиск всех возможных вариантов объектов БЗ. Граница между декларативными и процедурными знаниями очень подвижна, т.е. проектировщик может описать одно и то же как отношение или как правило. Во всех видах моделей выделен еще один вид знаний - метазнания, т.е. знания о данных. Метазнания могут задавать способы использования знаний, свойства знаний и т.д., т.е. все, что необходимо для управления логическим выводом и обучением ЭС. 3. Определение понятий логического вывода. Аппарат логического вывода предназначен для формирования новых понятий, т.е. решений в рамках определенной предметной области. Как правило логический вывод тесно связан с конкретной моделью знаний и оперирует терминологией этой модели. Есть несколько общих понятий для всех МЗ: стратегия вывода управляющая структура В ЭС применяется стратегия вывода в виде прямой и обратной цепочек рассуждения. Прямая стратегия ведет от фактов к гипотезам, а обратная пытается найти данные для доказательства или опровержения гипотезы. В современных ЭС применяются комбинированные стратегии, которые на одних этапах используют прямую, а на других обратную цепочки рассуждения. Управляющая структура - это способ применения или активизации правил в процессе формирования решений. Управляющая структура полностью зависит от выбранной проектировщиком модели. Например, для продукционной модели наиболее часто используются такие управляющие структуры: последовательный перебор правил одно подмножество правил применяется для выбора очередного правила Независимо от формы управляющей структуры в процессе поиска решений в некоторых точках поиска возникает необходимость выбора последующего направления поиска. Используется два метода: “сначала вглубь” “сначала вширь” Важной проблемой, которая требует обязательного решения в рамках аппарата логического вывода, является подтверждение или оценка достоверности формируемых системой частичных или общих решений. Трудность заключается в том, что ЭС как правило, работают с нечеткими, часто неопределенными понятиями, которые должны быть строго оценены и иметь четкую форму выражения. Термин “нечеткость” в ЭС недостаточно определен ив инженерии знаний используется такая классификация нечеткости: недетерминированность вывода многозначность ненадежность знаний неполнота неточность Под недетерминированностью вывода подразумевается возможность формирования плана решения задачи из определенных правил методом проб и ошибок, с возвратами при необходимости для построения других, более эффективных планов. С целью ускорения поиска эффективного плана в систему вводят оценочные функции разного вид, а также эвристические значения экспертов. Многозначность интерпретации знаний в процессе выработки решений устраняется за счет включения в систему более широкого контекста и семантических ограничений. Метод семантических ограничений называется методом релаксации. Суть его в том, что с помощью циклических операций применяются локальные ограничения, которые согласовываются между собой на верхнем уровне. Ненадежность. Для устранения ненадежности знаний, которая довольно часто используется в ЭС, используются методы основанные на нечеткой логике: расчет коэффициентов уверенности, метод Байеса и т.д. Нечеткая логика - разновидность непрерывной логики, в которой логические формулы могут принимать значения не только 0 или 1, но и все дробные значения между 0 и 1 для указания частичной истины. Наиболее слабое место в нечеткой логике - это реализация функции принадлежности, т.е. присваивание предпосылкам весовых значений экспертами (зависит от конкретного человека). Если tx и ty значения истинности предпосылок правил x и y, тогда при использовании логических связок “и/или” истинное значение предпосылки определяется следующим образом: - при связи “и” - tпредпосылки =min{tx,ty} - при связи “или” - tпредпосылки =max{tx,ty} Если в общем случае tправила есть истинное значение, приписываемое правилу, то тогда tправила определяется: tправила =min{tпредпосылки,tдействия}. Методы нечеткой логики: Коэффициент уверенности - это разница между двумя мерами: мерой доверия и мерой недоверия. КУ[h:e]=МД[h:e]-МНД[h:e] КУ[h:e] - коэффициент уверенности в гипотезе h с учетом свидетельств e, МД/МНД - мера доверия / недоверия. Коэффициент уверенности может принимать значения от -1 (абсолютная ложь) до +1 (абсолютная истина), а также все промежуточные значения между ними. При этом 0 означает полное незнание. Значения меры доверия и меры недоверия могут изменяться от 0 до 1. Основной недостаток: очень трудно отличить случай противоречивых свидетельств от случая недостаточной информации. В основе метода Байеса лежит оценка конкурирующих гипотез. Основная расчетная формула: ОП[h:e]=Р[h:e]/Р[h’:e] ОП - отношение правдоподобия, которое определяется как вероятность события или свидетельства e при условии заданной гипотезы h, деленное на вероятность этого свидетельства при условии ложности данной гипотезы h. 4. Неполные знания характерны для реального мира и предполагают наличие множества исключений и ограничений для конкретных высказываний, которые не принимаются во внимание, исходя из здравого смысла.
М,Ж - мягкие, жесткие знания. П,Г - поверхностные, глубинные знания. медицина, управление психодиагностика, планирование диагностика неисправностей разного вида проектирование различных видов устройств Обычно при проектировании БЗ проектировщик старается пользоваться стандартной моделью знаний (МЗ): продукционная модель знаний (системы продукции) логическая МЗ фреймовая МЗ реляционная МЗ По форме описания знания подразделяются на: Декларативные (факты) - это знания вида “А есть А”. Процедурные - это знания вида “Если А, то В”. Декларативные знания подразделяются на объекты, классы объектов и отношения. Объект - это факт, который задается своим значением. Класс объектов - это имя, под которым объединяется конкретная совокупность объектов-фактов. Отношения - определяют связи между классами объектов и отдельными объектами, возникшие в рамках предметной области. К процедурным знаниям относят совокупности правил, которые показывают, как вывести новые отличительные особенности классов или отношения для объектов. В правилах используются все виды декларативных знаний, а также логические связки. При обработке правил следует отметить рекурсивность анализа отношений, т.е. одно правило вызывает глубинный поиск всех возможных вариантов объектов БЗ. Граница между декларативными и процедурными знаниями очень подвижна, т.е. проектировщик может описать одно и то же как отношение или как правило. Во всех видах моделей выделен еще один вид знаний - метазнания, т.е. знания о данных. Метазнания могут задавать способы использования знаний, свойства знаний и т.д., т.е. все, что необходимо для управления логическим выводом и обучением ЭС. 3. Определение понятий логического вывода. Аппарат логического вывода предназначен для формирования новых понятий, т.е. решений в рамках определенной предметной области. Как правило логический вывод тесно связан с конкретной моделью знаний и оперирует терминологией этой модели. Есть несколько общих понятий для всех МЗ: стратегия вывода управляющая структура В ЭС применяется стратегия вывода в виде прямой и обратной цепочек рассуждения. Прямая стратегия ведет от фактов к гипотезам, а обратная пытается найти данные для доказательства или опровержения гипотезы. В современных ЭС применяются комбинированные стратегии, которые на одних этапах используют прямую, а на других обратную цепочки рассуждения. Управляющая структура - это способ применения или активизации правил в процессе формирования решений. Управляющая структура полностью зависит от выбранной проектировщиком модели. Например, для продукционной модели наиболее часто используются такие управляющие структуры: последовательный перебор правил одно подмножество правил применяется для выбора очередного правила Независимо от формы управляющей структуры в процессе поиска решений в некоторых точках поиска возникает необходимость выбора последующего направления поиска. Используется два метода: “сначала вглубь” “сначала вширь” Важной проблемой, которая требует обязательного решения в рамках аппарата логического вывода, является подтверждение или оценка достоверности формируемых системой частичных или общих решений. Трудность заключается в том, что ЭС как правило, работают с нечеткими, часто неопределенными понятиями, которые должны быть строго оценены и иметь четкую форму выражения. Термин “нечеткость” в ЭС недостаточно определен ив инженерии знаний используется такая классификация нечеткости: недетерминированность вывода многозначность ненадежность знаний неполнота неточность Под недетерминированностью вывода подразумевается возможность формирования плана решения задачи из определенных правил методом проб и ошибок, с возвратами при необходимости для построения других, более эффективных планов. С целью ускорения поиска эффективного плана в систему вводят оценочные функции разного вид, а также эвристические значения экспертов. Многозначность интерпретации знаний в процессе выработки решений устраняется за счет включения в систему более широкого контекста и семантических ограничений. Метод семантических ограничений называется методом релаксации. Суть его в том, что с помощью циклических операций применяются локальные ограничения, которые согласовываются между собой на верхнем уровне. Ненадежность. Для устранения ненадежности знаний, которая довольно часто используется в ЭС, используются методы основанные на нечеткой логике: расчет коэффициентов уверенности, метод Байеса и т.д. Нечеткая логика - разновидность непрерывной логики, в которой логические формулы могут принимать значения не только 0 или 1, но и все дробные значения между 0 и 1 для указания частичной истины. Наиболее слабое место в нечеткой логике - это реализация функции принадлежности, т.е. присваивание предпосылкам весовых значений экспертами (зависит от конкретного человека). Если tx и ty значения истинности предпосылок правил x и y, тогда при использовании логических связок “и/или” истинное значение предпосылки определяется следующим образом: - при связи “и” - tпредпосылки =min{tx,ty} - при связи “или” - tпредпосылки =max{tx,ty} Если в общем случае tправила есть истинное значение, приписываемое правилу, то тогда tправила определяется: tправила =min{tпредпосылки,tдействия}. Методы нечеткой логики: Коэффициент уверенности - это разница между двумя мерами: мерой доверия и мерой недоверия. КУ[h:e]=МД[h:e]-МНД[h:e] КУ[h:e] - коэффициент уверенности в гипотезе h с учетом свидетельств e, МД/МНД - мера доверия / недоверия. Коэффициент уверенности может принимать значения от -1 (абсолютная ложь) до +1 (абсолютная истина), а также все промежуточные значения между ними. При этом 0 означает полное незнание. Значения меры доверия и меры недоверия могут изменяться от 0 до 1. Основной недостаток: очень трудно отличить случай противоречивых свидетельств от случая недостаточной информации. В основе метода Байеса лежит оценка конкурирующих гипотез. Основная расчетная формула: ОП[h:e]=Р[h:e]/Р[h’:e] ОП - отношение правдоподобия, которое определяется как вероятность события или свидетельства e при условии заданной гипотезы h, деленное на вероятность этого свидетельства при условии ложности данной гипотезы h. 4. Неполные знания характерны для реального мира и предполагают наличие множества исключений и ограничений для конкретных высказываний, которые не принимаются во внимание, исходя из здравого смысла. В ЭС предполагается работа с неполными знаниями. При проектировании БЗ в базу вносятся всегда только верные знания, а неопределенные знания считаются неверными - гипотеза закрытого мира. 5 - Неточность вывода присутствует в ЭС и связана с тем, что в реальном мире система работает с нечеткими множествами, поэтому для устранения неточности используется теория нечетких множеств. 4. Организация интерфейса с пользователем в ЭС. В блоке “интерпретатор запросов и объяснение результатов” предназначен для функционирования системы в режиме эксплуатации при работе с конечным пользователем. Интерпретатор запросов формирует обращение пользователей к системе, а блок объяснения результатов комментирует весь ход формирования решения в системе. По теории ЭС оба эти блока должны иметь развитые средства общения с пользователем на языке, максимально приближенном к естественному. В настоящее время целое научное направление занимается вопросами создания интерфейса на естественном языке. Интерпретатор запросов производит редактирование обращения пользователя и формирует на его основе задачу для системы. В интерпретаторе должны быть предусмотрены средства устранения неопределенности запросов, а также производятся синтаксический и семантический анализ запроса. Неопределенность порождается, как правило, некомпетентностью пользователя. В некоторых случаях объективная оценка целого ряда факторов, описывающих конкретную ситуацию, может быть объективно невозможна. В интерпретаторе запросов предусматривается система уточняющих вопросов к пользователю, а также разрабатывается специальный аппарат, позволяющий на основе анализа контекста запроса назначить недостающие значения показателей по умолчанию. В запросе пользователя используется, как правило, декларативные знания, которые обязательно контролируются как на семантическом, так и на синтаксическом уровне. Интерпретатор преобразовывает декларативные знания запросов в те формализмы, которые используются в модели БЗ. Чем проще пользователю обращаться к системе на естественном языке, тем сложнее интерпретатор запросов. В блоке объяснения должно быть предусмотрено полное текстовое объяснение с использованием когнетивных функций всего хода решения задачи, а также описание стратегии поведения системы на сложных этапах выработки решений.
Блок обучения функционирует в режиме актуализации БЗ на этапе ее проектирования и эксплуатации и взаимодействует с экспертами предметной области. Его основная задача - это формализация знаний полученных от эксперта в соответствии с выбранной проектировщиком моделью знаний. В этом блоке объединяются функции интерпретатора запросов и блока объяснения. Блок объяснения должен реализовать общение с экспертом на естественном языке.
Продукционная модель (ПМ) знаний и ее использование в ЭС. Представление знаний. Особенности организации логического вывода. Организация поиска решений в простых и сложных ЭС. Примеры использования ПМ. 1. Представление знаний. ПМ или системы продукции используют для представления знаний два понятия: “объект-атрибут-значение” “правило продукции” С помощью (1) описываются декларативные знания в базе. Такое представление позволяет при формировании БЗ упорядочить описание объектов, соблюдая их определенную иерархию. Если к таким упорядоченным объектам в процессе логического вывода применять правила, то можно организовать обращение отдельно к объекту, отдельно к атрибуту и отдельно к значению. Правило продукции представляет собой средство описания процедурных знаний в виде MG->MD MG описывает определенную ситуацию в предметной области MD описывает собой одно действие или соволкупность действий, которые необходимо выполнить в случае обнаружения соответствующей ситуации в предметной области Применеие каждого текущего правила изменяет ситуацию на обьекте , поэтому нужно в следующем цикле проверить весь набор правил, пока не встретится условие останова. И левая и правая часть правила строится на основе знаний в виде “объект-атрибут-значение” или более сложных конструкций, построенных на их базе. Продукционные системы используют модульный принцип организации знаний (этим они отличаются от традиционных систем, т.к. те используют модульный принцип организации алгоритмов) В продукционных моделях предполагается полная независимость правил друг от друга, т.е. на одном уровне иерархии одно правило не может вызвать другое. Продукционные модели обладают высокой степенью модифицируемости значений, дают возможность четко отделить метазнания от предметных знаний, что позволяет даже врамках одной системы использовать разные стратегии вывода. 2. Особенности организации логического вывода. Механизм или аппарат логического вывода продукционной модели основан на принципе распознавания образов. Этот механизм называют интерпретатором,который циклически выполняет 4 последовательных этапа (выборку, сопоставление, разрешение конфликта, действие или их совокупность) На каждом из перечисленных этапов интерпретатор работает с БЗ, рабочей памятью, памятью состояний интерпретатора. Схема одного цикла работы интерпретатора следующая: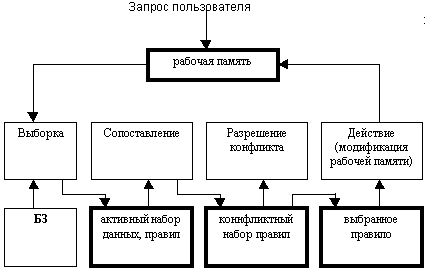 На этапе выборки производится активизация той части данных и знаний , на основании которых может быть реализован запрос пользователя. Активизация знаний производится на основе заложенной в системе стратегии вывода. Наиболее часто на этом этапе используется операции замены, добавления, удаления, с помощью которых пополняются перечни активных знаний и меняется порядок активизации обьектов. На этапе сопоставления, выбранное на предыдущем этапе множество активных правил Рv приводится в соответствие выбранному множеству элементов рабочей памяти Fv и определяется конфликтный набор правил, т.е. правил из Рv и данных из Fv, на которых эти правила определены. Конфликтный набор - упорядоченные последовательности Рv и Fv, который называется означивание. Этап сопоставления требует проведения значительного объема операций , т.к. для конфликтного набора следует проверить все условия правил на всех сочетаниях активных элементов рабочей памяти. В ходе разрешения конфликта интерпретатор выбирает одно или несколько означиваний, кот. д.б. выполнены в текущем цикле. Система строится таким образом, что на этом этапе предусматривается обязательная ее реакция на изменение окружающей Среды, а также предусм. возможность приобретения новых значений в тех случаях, когда возникают новые аспекты окружающей Среды. В ходе разрешения конфликта появляется необходимость координации действий нескольких правил, кот. по определению д.б. независимы. В зависимости от выбранной модели знаний, для разрешения конфликта м.б. использованы следующие управляющие структурыиначе порядок выбора правил: 1-я управляющая структура — упорядочивание правил 2-я управляющая структура — управляющая структура специальных случаев 3-я управляющая структура — возраста элемента 4-я управляющая структура — различий (подобия) 5-я управляющая структура — случайные стратегии (1) — используется в качестве критерия выбора означиваний приоритеты или оценки , кот. приписываются соответствующим правилам. В этом случае вводится понятие памяти правила. Оценочный показатель выбирается произвольно, чаще всего исходя из следующих критериев : 1 — динамический приоритет правила в зависимости от его вклада в достижение целей. 2 — динамический приоритет в зависимости от важности используемых фактов. (2) — исп. в качестве критерия зарание определенного отношения двух правил , такое что если первое правило является специальным случаем, то оно считается предпочтительным (3) — исп. в качестве критерия времени нахождения элемента в рабочей памяти. Обычно возраст определяется числом циклов работы инт-ра или числом действий, кот. выполнялись после создания элемента (4) — исп. в качестве критерия различия или подобия означиваний из текущего набора тем означиваниям, кот. были выполнены в пределах цикла (5) — явл. нежелательной, к ним приходится прибегать в тех случаях,когда после применения других стратегий не происходит выбора ниодного правила. К (5) можно отнести и исчерпывающий перебор правил. Он допустим в небольших по размеру БЗ в тех случаях,когда необходимо провести анализ всех возможных выводов и комбинаций. На этапе выполнения действий осуществляется изменение рабочей памяти посредством проведения операции ввода и преобразования текущих элементов. На этом этапе используется операция вывода для организации диалога с пользователем. На этом этапе производится проверка : не является ли текущее состояние рабочей памяти целевым, т.е. конечным. Если нет, то процесс вывода продолжается, начиная с этапа выборки. В продукционных системах можна выделить два подхода , исп. при выводе решений: 1 — безвозвратный 2 — пробный В (1) выбранное для выбранное для исполнения правило используется необратимо, т.е. без возможности дальнейшего пересмотра. В (2) применимое к конкретной ситуации правило также выполняется , но предусматривает возможность вернуться к этой ситуации, чтобы применить другое правило. Для этого режима предусматривается точка возврата и если на последующих этапах невозможно получить результат, то управление передается в последнюю точку возврата. 3. Организация поиска решений в простых и сложных ЭС. Процедуры поиска рашений зависят от особенностей предметной области и требований, кот. предьявляют пользователи к этим решениям. Особенности предметной области м.б. описаны следующими параметрами: 1 — размер предметной области 2 — изменяемость предметной области во времени ипространстве 3 — полнота модели, описаний предметной области 4 — определенность данных о решаемой задаче Требования пользователя в системе может описыв. следующ. параметрами: 1 — кол-во требуемых решений (одно применимое, несколько ,или все допустимые) 2 — ограничение на результат и способ его получения. Описанные с помощбю указанных пар в ЭС подраздел-ся на простые (малая статическая предметная область, полнота и определенность данных) и сложные. Для простых и сложных ЭС должны использ-ся различные процедуры поиска решений. Процедуры поиска решения значительно отличаются друг от друга в простых и сложных ЭС. Для простых ЭС чаще всего используют поиск в пространстве состояний : метод редукции, эвристический поиск. Метод поиск в пространстве состояний можно описать следующим образом: пусть задана тройка (S0,F,SТ) , где S0— множество начальных состояний системы (запрос) F— множество операторов, отображающих одни состояния в другие. ST— множество конечных целевых состояний системы Обработать задачу (запрос) — определить такую последовательность операторов, кот. позволит преобразовазовать начальное состояние системы в конечное. Процесс решения представляется в виде графа сигма=(x,y), где x=(x0,x1...xТ) множество бесконечных вершин графа, каждая из которых связана с определенными состояниями. y — множество пар (xi,xj), принадлеж. множ. X Если каждая пара (Xi;Xj) не упорядочена, то ее называют ребром графа, а граф неориентированным. Если для каждой пары (Xi;Xj) задан порядок, то ее называют дугой, а граф ориентированным. Наиболее часто метод используется для ориентированного графа. В этом случае решение задачи представляет собой путь на ориентированном графе, где пары (Xij-1;Xij) принадлежат Y, который приводит из начального состояния к целевому. На практике дугам графа приписывают весовые характеристики, которые отображают их приоритетность в процессе обработки запроса. В этом случае выбор пути сводится к минимизации или максимизации суммы весовых характеристик дуг, образующих этот путь. Таким образом граф j задает пространство возможных состояний предметной области. Построение пространства осуществляется с помощью следующей процедуры: берется некоторая вершина из множества начальных состояний и к ней применяются все возможные операторы, порождающие дочерние вершины. Этот процесс иначе называется “раскрытием вершин”. Он продолжается до тех пор, пока не будет найдена вершина, соответствующая одному из целевых состояний. Поиск может осуществляться либо в глубину, либо в ширину. При поиске в глубину начальная вершина получает значение 0, а глубина каждой следующей вершины равна 1 плюс значение глубины наиболее близкой родительской вершины. При поиске в ширину вершины раскрываются в том же порядке, что и порождаются. Если в пространстве состояний ввести операторы, переводящие текущие состояния в предыдущие, то поиск можно производить не только в прямом, но и в обратном направлении. Метод II - редукция. При поиске методом редукции решение задачи сводится к решению образующих ее подзадач. Процесс повторяется для каждой следующей подзадачи до тех пор, пока не будет найдено очевидное решение для всей их совокупности. Процесс разбиения задач на подзадачи представляется в виде ориентированного графа j, который называется “и/или-граф”. Каждая вершина “и/или-графа” представляет собой задачу или подзадачу и может быть конъюнктивной (“и”-вершиной) или дизъюнктивной (“или”-вершиной). Конъюнктивные вершины вместе со своими дочерними вершинами интерпретируются следующим образом: решение задачи сводится к решению всех ее подзадач, соответствующих дочерним вершинам конъюнктивной вершины. Дизъюнктивные вершины можно интерпретировать следующим образом: решение задачи сводится к решению " из ее подзадач, соответствующих дочерним вершинам дизъюнктивной вершины. Поиск на “и/или-графе” сводится к нахождению решающего графа для " начальной вершины. С целью сокращения времени поиска решений используются эвристические методы поиска. В основе эвристических методов заложена информация о специфике предметной области, которая позволяет сократить перебор вершин для достижения цели. Для этой группы методов характерно, что на каждой вершине используется эвристическая информация, которая перед раскрытием вершины позволяет определить степень ее перспективности для реализации определенного запроса. Оценка перспективности определяется на основе выбранной проектировщиком оценочной функции, в которой задаются различного рода семантические ограничения. Метод “генерация-проверка” позволяет в процессе поиска в пространстве состояний или подзадач генерировать очередное возможное решение и тут же проверить, не является ли оно конечным. Генератор решений должен быть очень полным, т.е. обеспечивать получение всех возможных решений и в то же время неизбыточным, т.е. генерировать одно решение только один раз. Проверка очередных сгенерированных решений производится на основе эвристических знаний, заложенных в генератор. Увеличение количества этих знаний приводит к сокращению пространства поиска решений, но в то же время увеличивает затраты на генерацию каждого решения. Для сложных ЭС применяются процедуры поиска, которые предназначены для роботы с теми видами сложности, которые присущи системе. Только для ЭС с большим размером пространства поиска целесообразно разбиение его на подпространства другого уровня иерархии. При этом могут выделяться подпространства, описывающие конкретные группы явлений предметной области, а также абстрактные пространства для описания каких-либо сущностей. Для последнего случая характерно использование неполных описаний, для которых в пространстве более низкого уровня дается определенная конкретизация. К методам поиска, реализованным по требованию пользователя полный состав решений в рамках большого пространства состояний, относят поиск в факторизованном пространстве. Факторизованным пространством называют пространство, которое можно разбить на непересекающиеся подпространства частичными неполными решениями. Здесь используется метод “иерархическая генерация-проверка”. Генератор определяет текущее частичное решение, затем проверяется, может ли привести это решение к успеху. Если текущее решение отвергается, то из рассмотрения без генерации и проверки устраняются все решения данного класса. И т.д. (очень много методов). 4. Примеры использования ПМ. MYCIN - система для диагностики и лечения инфекционных заболеваний. Был разработан скелетный язык, иначе - оболочка ЭС. Декларативные знания системы MYCIN описываются в виде “объект-атрибут-значение” и каждой тройке приписывается коэффициент уверенности, определяющий степень надежности знаний. Процедурные знания описаны в виде классического правила продукции. Механизм логического вывода основан на обратной цепочке рассуждений. Поиск производится в иерархически упорядоченном пространстве состояний. В системе EMYCIN (оболочка) усилена предметной области отношению к MYCIN функция редактирования БЗ, доведена до высокого уровня система объяснения хода решения задачи, а также аппарат обучения системы. Написан на ФОРТРАНе. OPS-5. Универсальный язык инженерии знаний, предназначенный для разработки ЭС, используемых в коммерческих приложениях. Разработчик - университет Корнеги-Меллон. Декларативные знания в системе описаны в виде “объект-атрибут-значение”. Процедурные знания описаны в виде классических правил продукции. В механизме логического вывода используется стратегия прямой цепочки рассуждений, реализуется метод применения одного и того же правила в различных контекстах; для формирования конфликта набора и разрешения конфликта используются специальные методы {RETELEX}, которые позволяют добиться высокой эффективности за счет управляющей структуры, где предпочтение отдается правилам со ссылкой на самый последний сгенерированный элемент “объект-атрибут-значение”. Методология построения ЭС. 1. Подход к проектированию ЭС. 2. Содержание этапов проектирования. 3. Практические аспекты разработки и внедрения ЭС. 1. Подход к проектированию ЭС. Проектирование ЭС имеет существенное отличие от проектирования традиционных информационных систем в силу того, что постановка задач, решаемых экспертной системой может уточняться во время всего цикла проектирования. Вследствие этого возникает потребность модифицировать принципы и способы построения базы знаний и аппарата лгического вывода в ходе проектирования по мере того, как увеличивается объем знаний разработчиков о предметной области. В силу отмеченных особенностей при проектировании ЭС-м применяется концепция “быстрого прототипа”. Ее суть: разработчики не пытаются сразу построить законченный продукт. На начальном этапе создается прототип, к-рый должен удовлетворять двум условиям: 1) он должен решать типичные задачи предметной области; 2) с другой стороны трудоемкость его разработки должна быть очень незначительной. Для удовлетворения этих условий при создании прототипа используются инструментальные средства, позволяющие ускорить процесс программирования ЭС (скелетные языки, оболочки ЭС). В случае успеха прототип должен расширяться дополнительными знаниями из предметной области. При неудаче может потребоваться разработка нового прототипа или проектировщики могут прийти к выводу о непригодности методов искуственного интеллекта для данного приложения. По мере увеличения знаний о предметной области прототип может достичь такого состояния, когда он успешно решает все требуемые задачи в рамках предметной области. В этом случае требуется преобразование прототипа в конечный продукт путем его перепрограммирования на языках “низкого уровня”, что обеспечит увеличение быстродействия и эффективности программного продукта.
На этапе выборки производится активизация той части данных и знаний , на основании которых может быть реализован запрос пользователя. Активизация знаний производится на основе заложенной в системе стратегии вывода. Наиболее часто на этом этапе используется операции замены, добавления, удаления, с помощью которых пополняются перечни активных знаний и меняется порядок активизации обьектов. На этапе сопоставления, выбранное на предыдущем этапе множество активных правил Рv приводится в соответствие выбранному множеству элементов рабочей памяти Fv и определяется конфликтный набор правил, т.е. правил из Рv и данных из Fv, на которых эти правила определены. Конфликтный набор - упорядоченные последовательности Рv и Fv, который называется означивание. Этап сопоставления требует проведения значительного объема операций , т.к. для конфликтного набора следует проверить все условия правил на всех сочетаниях активных элементов рабочей памяти. В ходе разрешения конфликта интерпретатор выбирает одно или несколько означиваний, кот. д.б. выполнены в текущем цикле. Система строится таким образом, что на этом этапе предусматривается обязательная ее реакция на изменение окружающей Среды, а также предусм. возможность приобретения новых значений в тех случаях, когда возникают новые аспекты окружающей Среды. В ходе разрешения конфликта появляется необходимость координации действий нескольких правил, кот. по определению д.б. независимы. В зависимости от выбранной модели знаний, для разрешения конфликта м.б. использованы следующие управляющие структурыиначе порядок выбора правил: 1-я управляющая структура — упорядочивание правил 2-я управляющая структура — управляющая структура специальных случаев 3-я управляющая структура — возраста элемента 4-я управляющая структура — различий (подобия) 5-я управляющая структура — случайные стратегии (1) — используется в качестве критерия выбора означиваний приоритеты или оценки , кот. приписываются соответствующим правилам. В этом случае вводится понятие памяти правила. Оценочный показатель выбирается произвольно, чаще всего исходя из следующих критериев : 1 — динамический приоритет правила в зависимости от его вклада в достижение целей. 2 — динамический приоритет в зависимости от важности используемых фактов. (2) — исп. в качестве критерия зарание определенного отношения двух правил , такое что если первое правило является специальным случаем, то оно считается предпочтительным (3) — исп. в качестве критерия времени нахождения элемента в рабочей памяти. Обычно возраст определяется числом циклов работы инт-ра или числом действий, кот. выполнялись после создания элемента (4) — исп. в качестве критерия различия или подобия означиваний из текущего набора тем означиваниям, кот. были выполнены в пределах цикла (5) — явл. нежелательной, к ним приходится прибегать в тех случаях,когда после применения других стратегий не происходит выбора ниодного правила. К (5) можно отнести и исчерпывающий перебор правил. Он допустим в небольших по размеру БЗ в тех случаях,когда необходимо провести анализ всех возможных выводов и комбинаций. На этапе выполнения действий осуществляется изменение рабочей памяти посредством проведения операции ввода и преобразования текущих элементов. На этом этапе используется операция вывода для организации диалога с пользователем. На этом этапе производится проверка : не является ли текущее состояние рабочей памяти целевым, т.е. конечным. Если нет, то процесс вывода продолжается, начиная с этапа выборки. В продукционных системах можна выделить два подхода , исп. при выводе решений: 1 — безвозвратный 2 — пробный В (1) выбранное для выбранное для исполнения правило используется необратимо, т.е. без возможности дальнейшего пересмотра. В (2) применимое к конкретной ситуации правило также выполняется , но предусматривает возможность вернуться к этой ситуации, чтобы применить другое правило. Для этого режима предусматривается точка возврата и если на последующих этапах невозможно получить результат, то управление передается в последнюю точку возврата. 3. Организация поиска решений в простых и сложных ЭС. Процедуры поиска рашений зависят от особенностей предметной области и требований, кот. предьявляют пользователи к этим решениям. Особенности предметной области м.б. описаны следующими параметрами: 1 — размер предметной области 2 — изменяемость предметной области во времени ипространстве 3 — полнота модели, описаний предметной области 4 — определенность данных о решаемой задаче Требования пользователя в системе может описыв. следующ. параметрами: 1 — кол-во требуемых решений (одно применимое, несколько ,или все допустимые) 2 — ограничение на результат и способ его получения. Описанные с помощбю указанных пар в ЭС подраздел-ся на простые (малая статическая предметная область, полнота и определенность данных) и сложные. Для простых и сложных ЭС должны использ-ся различные процедуры поиска решений. Процедуры поиска решения значительно отличаются друг от друга в простых и сложных ЭС. Для простых ЭС чаще всего используют поиск в пространстве состояний : метод редукции, эвристический поиск. Метод поиск в пространстве состояний можно описать следующим образом: пусть задана тройка (S0,F,SТ) , где S0— множество начальных состояний системы (запрос) F— множество операторов, отображающих одни состояния в другие. ST— множество конечных целевых состояний системы Обработать задачу (запрос) — определить такую последовательность операторов, кот. позволит преобразовазовать начальное состояние системы в конечное. Процесс решения представляется в виде графа сигма=(x,y), где x=(x0,x1...xТ) множество бесконечных вершин графа, каждая из которых связана с определенными состояниями. y — множество пар (xi,xj), принадлеж. множ. X Если каждая пара (Xi;Xj) не упорядочена, то ее называют ребром графа, а граф неориентированным. Если для каждой пары (Xi;Xj) задан порядок, то ее называют дугой, а граф ориентированным. Наиболее часто метод используется для ориентированного графа. В этом случае решение задачи представляет собой путь на ориентированном графе, где пары (Xij-1;Xij) принадлежат Y, который приводит из начального состояния к целевому. На практике дугам графа приписывают весовые характеристики, которые отображают их приоритетность в процессе обработки запроса. В этом случае выбор пути сводится к минимизации или максимизации суммы весовых характеристик дуг, образующих этот путь. Таким образом граф j задает пространство возможных состояний предметной области. Построение пространства осуществляется с помощью следующей процедуры: берется некоторая вершина из множества начальных состояний и к ней применяются все возможные операторы, порождающие дочерние вершины. Этот процесс иначе называется “раскрытием вершин”. Он продолжается до тех пор, пока не будет найдена вершина, соответствующая одному из целевых состояний. Поиск может осуществляться либо в глубину, либо в ширину. При поиске в глубину начальная вершина получает значение 0, а глубина каждой следующей вершины равна 1 плюс значение глубины наиболее близкой родительской вершины. При поиске в ширину вершины раскрываются в том же порядке, что и порождаются. Если в пространстве состояний ввести операторы, переводящие текущие состояния в предыдущие, то поиск можно производить не только в прямом, но и в обратном направлении. Метод II - редукция. При поиске методом редукции решение задачи сводится к решению образующих ее подзадач. Процесс повторяется для каждой следующей подзадачи до тех пор, пока не будет найдено очевидное решение для всей их совокупности. Процесс разбиения задач на подзадачи представляется в виде ориентированного графа j, который называется “и/или-граф”. Каждая вершина “и/или-графа” представляет собой задачу или подзадачу и может быть конъюнктивной (“и”-вершиной) или дизъюнктивной (“или”-вершиной). Конъюнктивные вершины вместе со своими дочерними вершинами интерпретируются следующим образом: решение задачи сводится к решению всех ее подзадач, соответствующих дочерним вершинам конъюнктивной вершины. Дизъюнктивные вершины можно интерпретировать следующим образом: решение задачи сводится к решению " из ее подзадач, соответствующих дочерним вершинам дизъюнктивной вершины. Поиск на “и/или-графе” сводится к нахождению решающего графа для " начальной вершины. С целью сокращения времени поиска решений используются эвристические методы поиска. В основе эвристических методов заложена информация о специфике предметной области, которая позволяет сократить перебор вершин для достижения цели. Для этой группы методов характерно, что на каждой вершине используется эвристическая информация, которая перед раскрытием вершины позволяет определить степень ее перспективности для реализации определенного запроса. Оценка перспективности определяется на основе выбранной проектировщиком оценочной функции, в которой задаются различного рода семантические ограничения. Метод “генерация-проверка” позволяет в процессе поиска в пространстве состояний или подзадач генерировать очередное возможное решение и тут же проверить, не является ли оно конечным. Генератор решений должен быть очень полным, т.е. обеспечивать получение всех возможных решений и в то же время неизбыточным, т.е. генерировать одно решение только один раз. Проверка очередных сгенерированных решений производится на основе эвристических знаний, заложенных в генератор. Увеличение количества этих знаний приводит к сокращению пространства поиска решений, но в то же время увеличивает затраты на генерацию каждого решения. Для сложных ЭС применяются процедуры поиска, которые предназначены для роботы с теми видами сложности, которые присущи системе. Только для ЭС с большим размером пространства поиска целесообразно разбиение его на подпространства другого уровня иерархии. При этом могут выделяться подпространства, описывающие конкретные группы явлений предметной области, а также абстрактные пространства для описания каких-либо сущностей. Для последнего случая характерно использование неполных описаний, для которых в пространстве более низкого уровня дается определенная конкретизация. К методам поиска, реализованным по требованию пользователя полный состав решений в рамках большого пространства состояний, относят поиск в факторизованном пространстве. Факторизованным пространством называют пространство, которое можно разбить на непересекающиеся подпространства частичными неполными решениями. Здесь используется метод “иерархическая генерация-проверка”. Генератор определяет текущее частичное решение, затем проверяется, может ли привести это решение к успеху. Если текущее решение отвергается, то из рассмотрения без генерации и проверки устраняются все решения данного класса. И т.д. (очень много методов). 4. Примеры использования ПМ. MYCIN - система для диагностики и лечения инфекционных заболеваний. Был разработан скелетный язык, иначе - оболочка ЭС. Декларативные знания системы MYCIN описываются в виде “объект-атрибут-значение” и каждой тройке приписывается коэффициент уверенности, определяющий степень надежности знаний. Процедурные знания описаны в виде классического правила продукции. Механизм логического вывода основан на обратной цепочке рассуждений. Поиск производится в иерархически упорядоченном пространстве состояний. В системе EMYCIN (оболочка) усилена предметной области отношению к MYCIN функция редактирования БЗ, доведена до высокого уровня система объяснения хода решения задачи, а также аппарат обучения системы. Написан на ФОРТРАНе. OPS-5. Универсальный язык инженерии знаний, предназначенный для разработки ЭС, используемых в коммерческих приложениях. Разработчик - университет Корнеги-Меллон. Декларативные знания в системе описаны в виде “объект-атрибут-значение”. Процедурные знания описаны в виде классических правил продукции. В механизме логического вывода используется стратегия прямой цепочки рассуждений, реализуется метод применения одного и того же правила в различных контекстах; для формирования конфликта набора и разрешения конфликта используются специальные методы {RETELEX}, которые позволяют добиться высокой эффективности за счет управляющей структуры, где предпочтение отдается правилам со ссылкой на самый последний сгенерированный элемент “объект-атрибут-значение”. Методология построения ЭС. 1. Подход к проектированию ЭС. 2. Содержание этапов проектирования. 3. Практические аспекты разработки и внедрения ЭС. 1. Подход к проектированию ЭС. Проектирование ЭС имеет существенное отличие от проектирования традиционных информационных систем в силу того, что постановка задач, решаемых экспертной системой может уточняться во время всего цикла проектирования. Вследствие этого возникает потребность модифицировать принципы и способы построения базы знаний и аппарата лгического вывода в ходе проектирования по мере того, как увеличивается объем знаний разработчиков о предметной области. В силу отмеченных особенностей при проектировании ЭС-м применяется концепция “быстрого прототипа”. Ее суть: разработчики не пытаются сразу построить законченный продукт. На начальном этапе создается прототип, к-рый должен удовлетворять двум условиям: 1) он должен решать типичные задачи предметной области; 2) с другой стороны трудоемкость его разработки должна быть очень незначительной. Для удовлетворения этих условий при создании прототипа используются инструментальные средства, позволяющие ускорить процесс программирования ЭС (скелетные языки, оболочки ЭС). В случае успеха прототип должен расширяться дополнительными знаниями из предметной области. При неудаче может потребоваться разработка нового прототипа или проектировщики могут прийти к выводу о непригодности методов искуственного интеллекта для данного приложения. По мере увеличения знаний о предметной области прототип может достичь такого состояния, когда он успешно решает все требуемые задачи в рамках предметной области. В этом случае требуется преобразование прототипа в конечный продукт путем его перепрограммирования на языках “низкого уровня”, что обеспечит увеличение быстродействия и эффективности программного продукта.Кол-во разработчиков ЭС не должно быть меньше 4 чел., из к-рых 1 явл-ся экспертом ПО, 2 - инженеры по знаниям или проектировщики ЭС, 1 - программист, осуществляющий модификацию и согласование инструментальных средств.
В дальнейшем, в процессе преобразования прототипа в конечный продукт, состав программистов должен быть увеличен. 2. Основные этапы разработки ЭС.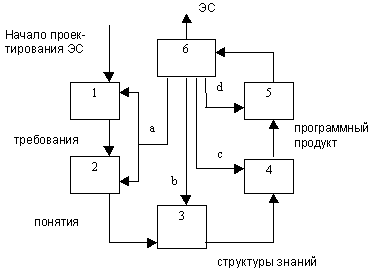 1. Идентификация. 2. Концептуализация. 3. Формализация. 4. Выполнение. 6. Тестирование. a. Переформулирование b. Переконструирование c. Усовершенствование d. Завершение В состав функций этапа 1 входит: 1) определение команды проектировщиков, их роли, а также формы взаимоотоношений; 2) определение целей разработок и ресурсов; 3) описание общих характеристик проблемы, входных данных, предполагаемого вида решения, ключевых понятий и отношений. Типичные ресурсы этого этапа: источники знаний, время разработки, вычислительные ресурсы, объем финансирования. На этапе 2 эксперт и инжинер по знаниям формализуют ключевые понятия, отношения и характеристики, которые выявлены на предыдущем этапе. Данный этап призвн решить следующие вопросы: определить типы данных, выводимые понятия, используемые стратегии и гипотезы, виды взаимосвязей между объектами, типы ограничений, накладываемых на процесс решения задачи, состав знаний, которые используются для выработки и обоснования решений. Опыт показывает, что для успешного решения вопросов этого этапа целесообразно составлять протокол действий и рассуждений экспертов в процессе проектирования. Такой протокол обеспечивает инженера по знаниям словарем терминов и вто же время заставляет эксперта осмысленно относиться к своим словам. На этом этапе не требуется добиваться полной определенности и корректности всех заключений, а следует наметить лишь основные типовые направления решения проблемы. На этапе 3 производится описание всех ключевых понятий и отношений на формальном языке. Инженер по знаниям производит анализ инструментальных систем и определяет их пригодность для конкретного приложения. Выходом данного этапа является формальное описание всего процесса решения жадачи на уровне декларативных и процедурных знаний. Инженер по знаниям определяет структуру пространства поиска решений, выбирает и обосновывает модель знаний, определяет состав метазнаний, которые затем могут быть положены в механизм логического вывода. При работе со знаниями изучается степень их достоверности, согласованность и избыточность, реализуется функция принадлежности различных оценочных показателей (например, коэффициентов уверенности), а также закладывается определенная интерпретация знаний в формальных структурах. Этап 4 заключается в разработке одного или нескольких прототипов. Этот этап выполняется программистом и заключается в наполнении базы знаний инструментальной системы конкретными знаниями, а также программировании отдельных компонент системы. Обычная ошибка программиста заключается в том, что процесс наполнения базы знаний реальными знаниями откладывается до окончания программирования. Если база знаний заполняется с начала разработки прототипа, то это позволяет своевременно уточнить структуру знаний и быстро изменить программные компоненты. Первый прототип должен быть готов уже через 2 месяца. При работе с ним программист доказывает, что выбранные структуры и методы пригодны для данного приложения и могут быть в дальнейшем расширены. При этом он совсем не заботится об эффективности машинной реализации. После завершения первого прототипа круг задач расширяется и на этой основе формируется следующий прототип. После достижения достаточно эффективного функционирования ЭС на базе прототипов, совершенствуются структуры декларативных и процедурных знаний, а также процедуры логического вывода. Основная трудность состоит в том, что очень часто в системе имеются громоздкие правила или много похожих правил. Неверно выбранные управляющие стратегии, в которых порядок выбора и анализа понятий существенно отличается от технологии эксперта. На этом этапе очень важно посвящать эксперта во все проблемы, связанные с получением решений, и внимательно проводить анализ мнения эксперта о недостатках системы. Этап 5 оценивает пригодность ЭС для конечного пользователя. При этом разработчики стараются привлечь как можно больше пользователей различной квалификации, которые могут обращаться к системе для реализации разнообразных запросов. Для того, чтобы не дискредитировать систему в глазах пользователя, разработчики перед этим этапом должны устранить все ошибки в работе системы, даже мелкие технические ошибки. Пользователь анализирует систему с точки зрения полезности (возможность системы в ходе диалога определить потребности пользователя, выявить и устранить причины его неудач в работе) и удобства (настраиваемость на уровень квалификации пользователя, а также устойчивость к ошибкам). По результатам 5-го этапа может понадобиться не только модификация программного обеспечения, но и идеологии разработки интерфейса. Этап 6. Призван осуществлять оценку системы в целом. Тут необходимо особое внимание уделить подбору тестовых примеров. В них должны найти отражение следующие случаи: неверно сформулированныые вопросы пользователя; присутствие неопределенности в вопросах пользователя; доступность для пользователя лексики системы; доступность для пользователя объяснений, которые выдает система; проиворечивость и неполнота правил; согласование контекстов действия правил. По результатам 6-го этапа осуществляется модификация системы. Наиболее простым её видом явл-ся усовершенствование прототипов. Этот вид затрагивает только этапы 4 и 6. Более серьёзным видом модификации явл-ся переконструирование представлений. Этот вид модификации необходим в том случае, если обнаруживается, что желаемое поведение системы не достигнуто. Предполагается возврат на этап формализации и далее осуществляется весь цикл проектирования. Если проблемы функционирования системы еще более серьёзны, то приходится возвращаться на этапы 2 и 1 для переформулирования требований к системе и основных понятий. 3. Практические аспекты разработки и внедрения ЭС. В соответствии с результатами тестирования ЭС может находиться на одной из следующих стадий: 1) демонстрационный прототип (решает только часть задач в рамках ПО, демонстрируя правильность выбранного аппарата логического вывода). Срок доведения системы до этой стадии - около 3-х мес., кол-во правил в базе знаний - 50-100. 2) исследовательский прототип (решает все задачи в рамках ПО, на недостаточно устойчива в работе, не полностью проверена). Срок доведения - 1-2 года, кол-во правил - 200-500. 3) действующий прототип (решает стабильно все задачи в рамках ПО, но недостаточно эффективна в работе, в том числе нерациональное использование памяти, невысокое быстродействие). 2-3 г., 500-1000. 4) промышленная система (обеспчивает эффективную работу и высокое качество решений, содержит по сравнению со стадией 3 намного больше правил в базе знаний, программное обеспечение по сравнению с 3) переписано на язык низкого уровня). 2-4 г., 1000-1500. 5) коммерческая система (предполагает обобщение задач, уход от специфики ПО, предназначается для продажи другим потребителям. Развита по сравнинию с 4) система редактирования знаний, интерфейса с конкретным пользователем, обучения). 3-6 лет, 1000-3000. В процессе проектирования ЭС следует учитывать тот отрицательный опыт, который накоплен разработчиками на каждой стадии проектирования. На этапе 1 может оказаться, что система или задача настолько трудна, что её нельзя реализовать в рамках выдеенной проектировщиком системы ресурсов (время, деньги и т. д.). Проектировщики должны очень внимательно подойти к вопросу, сможет ли решение задачи принести существенную пользу, для пресонала, который её эксплуатирует. Следует учесть, что для сокращения времени проектирования нельзя расширять состав проектировщиков, так как процесс проектирования итеративный и категории проектировщиков не могут в сжатые сроки осмыслить все этапы проектирования. Традиционной ошибкой этапа 3 явл-ся подгонка инструментального средства под понятия и взаимосвязи конкретной ПО. Нельзя соглашаться при разработке прототипа на программирования сразу же на языках низкого уровня, т. е. без использования инструментальной системы. На всех стадиях проектирования инженер по знаниям работает с экспертом и при этом возникает целый ряд трудностей, которые заранее надо учитывать: эксперты всегда должны быть высококвалифицированными, их нужно заинтересовывать материально; эксперт никогда не может найти время на работу с инженером по знаниям; в системе обязательно должна использоваться та же терминология, что и у экспертов ПО; только в этом случае эксперт может успешно понимать структуру базы знаний и вносить в неё соответствующие изменения; с течением времени эксперт теряет интерес к проекту системы и постоянно сокращает время работы с проектировщиком. Для устранения этого проектировщик вносит изменения в систему только вместе с экспертом, тестирует также вместе с ним; эксперт незнаком, как правило, с компьютером, поэтому РС устанавливается на его рабочем месте и доработка системы производится там же; при извлечении знаний эксперта проектировщику очень трудно отделить знания ПО от метазнаний, поэтому работа с экспертом должна происходить не по всем вопросам в целом, а по строго спланированным инженером по знаниям порциям. На этапе 4 при разработке прототипа следует стремиться не разрабатывать самостоятельно средства объяснения, а использовать только те, что есть в инструментальной системе. При разработке первого прототипа необходимо стремиться к тому, чтобы в базу знаний попали простые универсальные правила и сокращать количество специфических правил. На этапе 6 следует учитывать, что если размер правил превышает 300, то их исправление и добавление может привести к появлению новых ошибок, поэтому должен существовать специальный тест, который проверяет систему на непротиворечивость правил. Особенности реализации экспертных систем на базе логической модели знаний. 1. Понятие логической модели знаний. 2. Характеристика языка предикатов первого порядка. Особенности представления знаний. 3. Аппарат логического вывода. 4. Особенности машинной реализации языка предикатов первого порядка. 1. Понятие логической модели знаний. В основе лог. модели знаний лежит понятие формальной теории и отношения, которые существуют между единицами знаний можно описывать только с помощью синтаксических правил, допустимых в рамках этой теории. Формальная теория задается всегда четверкой символов S=, где В - конечное множество базовых символов, иначе - алфавит теории S; F - подмножество выражений теории S, называемых формулами теории. Обычно имеется эффективная процедура, которая представляет собой совокупность правил, позволяющих из элементов множества В строить синтаксически правильные выражения. А - выделенное множество правил, называемых аксиомами теории, т. е. множество априорно истинных формул. R - конечное множество отношений { r1, r2, ... , rn } между формулами, называемыми правилами вывода. Для любого ri существует целое положительное число j, такое, что для каждого множества, состоящего из j формул, и для каждой формулы F эффективно решается вопрос о том, находятся ли эти j-формулы в отношении ri с формулой F. Если ri выполняется, то F называют непосредственным следствием F-формул по правилу ri. Следствием (выводом) формулы в теории S называется такая последовательность правил, что для любого из них представленная формула явл-ся либо аксиомой теории S, либо непосредственным следствием. Правила вывода, которые разрабатываются проектировщиками, позволдяют расширить множество формул, которые явл-ся аксиомами теории. Формальная теория наз. разрешимой, если существует эффективная процедура, позволяющая узнать для любой заданной формулы, существует ли её вывод в теории S. Формальная теория S наз. Непротиаворечивой, если не существует такой формулы А, что и А, и не А выводимы в данной теории. Наиболее распространенной формальной теорией, используемой в системах искуственного интеллекта явл-ся исчисление предикатов, то есть функций, которые могут принимать только 2 значения. К достоинствам логической модели относят: - наличие стандартной типовой процедуры логического вывода (доказательства теорем). Однако такое единообразие влечет за собой основной недостаток модели - сложность использования в процессе логического вывода эвристик, отражающих специфику ПО. К другим недостаткам логической модели относят: - “монотонность”; - “комбинаторный взрыв”; - слабость структурированности описаний. 2. Характеристика языка предикатов первого порядка. Особенности представления знаний. В основе языка предикатов первого порядка лежит понятие предикатов, то есть логическая функция от одной или нескольких нелогических пременных. Функция может принимать значения истина (t) или ложь (f). В рамках логики утверждение считается истинным, если и относящееся к нему предположение считается истинным и заключение самого утверждения тоже истина. Синтаксис языка предикатов включает: предикативные символы, символы переменных, константы (?), а также разделители ( ), [ ], “, ‘. Предикативные символы используются для обозначения отношений. Объекты отношений записываются в ( ) после предикативного символа и наз-ся аргументами. Полная запись отношения наз-ся атомной или атомарной формулой. Атомарная формула: Является ( Иванов, спец.—поЭВМ) предикативный терм 1 терм 2 символ Термы могут представляться констанатами и переменными. Разрешено также в качестве термов использовать функции, к-рые обязательно должны быть определены в рамках ПО. Проектировщик ЭС заранеее определяет, как интерпретировать порядок термов в отношении. Допустимые выражения в исчислении предикатов, в частности атомарные формулы, наз-ся правильно построенными функциями ( ППФ ). В языке предикатов для каждой ППФ обязательно определяется конкретная интерпретация. Как только для ППФ определена интерпретация, говорят, что формула имеет значение “истина”, если соответствующее утверждение ПО истинно, в противном случае ППФ имеет значение “ложь”. Из формул можно составить предложение с помощью логических связок: конъюнкция, дизъюнкция, импликация, отрицание. Конъюнкция ( ) используется для образования составных фраз: Учится ( Иванов, эк.-университет ) располагается ( эк.-университет, Киев ) ППФ, построенные с помощью связки конъюнкция, наз-ся просто конъюнкциями. Дизъюнкция ( ) реализует функцию не исключающего “или”. Находятся ( Иванов, аудит.-147) И находится ( Иванов, библиотека ). ППФ, построенные с помощью связки дизъюнкция, наз-ся дизъюнкциями. Связка импликация ( ) используется для представления утверждения типа “если, то”. Владеть ( Иванов, машина-1) марка ( машина-1, “BMW”). ППФ, построенная путем соединения формул с помощью связки импликация, наз-ся импликацией. Левая сторона импликации наз-ся антецедент, правая - конциквент. Импликация имеет значение “истина”, если антецедент и конциквент имеют значения “истина”, либо антецедент имеет значение “ложь” независимо от конциквента. В остальных случаях импликация имеет значения “ложь”. ППФ со знаком отрицания ( ~ ) пред ней наз-ся отрицанием. В языке предикатов атомная формула может принимать только истинные значения, только ложные значения, а также в зависимости от значений переменных, которые в нее входят, либо итсина, либо ложь. Для того, чтобы при исчислении предикатов можно было манипулировать значениями переменных, потребовалось ввести понятие “квантор”. Квантор - это операция, в которой участвуют все значения переменной одного предиката. Квантор служит для указания меры, в какой экземпляры переменной (?), то есть константы должны быть истинными, чтобы все значения в целом были истинными. Различают квантор общности и квантор сущестовования . Если перед предикатом записан квантор для какой-то переменной, напр. (х), то это означает, что значение предиката будет истинным только в том случае, если все значения переменной х будут истинными. (х) ( специалист-по-ЭВМ (х) программист ) Если перед предикатом записан квантор , напр. (х), то для истинности предиката достаточно, чтобы только некотрые значения переменной, по крайней мере одно, были истинными. (х) ( специалист-по-ЭВМ(х) оптимист(х) ) В рамках одного предиката можно использовать и кванторы общности, и кванторы существования, но для разных переменных.
1. Идентификация. 2. Концептуализация. 3. Формализация. 4. Выполнение. 6. Тестирование. a. Переформулирование b. Переконструирование c. Усовершенствование d. Завершение В состав функций этапа 1 входит: 1) определение команды проектировщиков, их роли, а также формы взаимоотоношений; 2) определение целей разработок и ресурсов; 3) описание общих характеристик проблемы, входных данных, предполагаемого вида решения, ключевых понятий и отношений. Типичные ресурсы этого этапа: источники знаний, время разработки, вычислительные ресурсы, объем финансирования. На этапе 2 эксперт и инжинер по знаниям формализуют ключевые понятия, отношения и характеристики, которые выявлены на предыдущем этапе. Данный этап призвн решить следующие вопросы: определить типы данных, выводимые понятия, используемые стратегии и гипотезы, виды взаимосвязей между объектами, типы ограничений, накладываемых на процесс решения задачи, состав знаний, которые используются для выработки и обоснования решений. Опыт показывает, что для успешного решения вопросов этого этапа целесообразно составлять протокол действий и рассуждений экспертов в процессе проектирования. Такой протокол обеспечивает инженера по знаниям словарем терминов и вто же время заставляет эксперта осмысленно относиться к своим словам. На этом этапе не требуется добиваться полной определенности и корректности всех заключений, а следует наметить лишь основные типовые направления решения проблемы. На этапе 3 производится описание всех ключевых понятий и отношений на формальном языке. Инженер по знаниям производит анализ инструментальных систем и определяет их пригодность для конкретного приложения. Выходом данного этапа является формальное описание всего процесса решения жадачи на уровне декларативных и процедурных знаний. Инженер по знаниям определяет структуру пространства поиска решений, выбирает и обосновывает модель знаний, определяет состав метазнаний, которые затем могут быть положены в механизм логического вывода. При работе со знаниями изучается степень их достоверности, согласованность и избыточность, реализуется функция принадлежности различных оценочных показателей (например, коэффициентов уверенности), а также закладывается определенная интерпретация знаний в формальных структурах. Этап 4 заключается в разработке одного или нескольких прототипов. Этот этап выполняется программистом и заключается в наполнении базы знаний инструментальной системы конкретными знаниями, а также программировании отдельных компонент системы. Обычная ошибка программиста заключается в том, что процесс наполнения базы знаний реальными знаниями откладывается до окончания программирования. Если база знаний заполняется с начала разработки прототипа, то это позволяет своевременно уточнить структуру знаний и быстро изменить программные компоненты. Первый прототип должен быть готов уже через 2 месяца. При работе с ним программист доказывает, что выбранные структуры и методы пригодны для данного приложения и могут быть в дальнейшем расширены. При этом он совсем не заботится об эффективности машинной реализации. После завершения первого прототипа круг задач расширяется и на этой основе формируется следующий прототип. После достижения достаточно эффективного функционирования ЭС на базе прототипов, совершенствуются структуры декларативных и процедурных знаний, а также процедуры логического вывода. Основная трудность состоит в том, что очень часто в системе имеются громоздкие правила или много похожих правил. Неверно выбранные управляющие стратегии, в которых порядок выбора и анализа понятий существенно отличается от технологии эксперта. На этом этапе очень важно посвящать эксперта во все проблемы, связанные с получением решений, и внимательно проводить анализ мнения эксперта о недостатках системы. Этап 5 оценивает пригодность ЭС для конечного пользователя. При этом разработчики стараются привлечь как можно больше пользователей различной квалификации, которые могут обращаться к системе для реализации разнообразных запросов. Для того, чтобы не дискредитировать систему в глазах пользователя, разработчики перед этим этапом должны устранить все ошибки в работе системы, даже мелкие технические ошибки. Пользователь анализирует систему с точки зрения полезности (возможность системы в ходе диалога определить потребности пользователя, выявить и устранить причины его неудач в работе) и удобства (настраиваемость на уровень квалификации пользователя, а также устойчивость к ошибкам). По результатам 5-го этапа может понадобиться не только модификация программного обеспечения, но и идеологии разработки интерфейса. Этап 6. Призван осуществлять оценку системы в целом. Тут необходимо особое внимание уделить подбору тестовых примеров. В них должны найти отражение следующие случаи: неверно сформулированныые вопросы пользователя; присутствие неопределенности в вопросах пользователя; доступность для пользователя лексики системы; доступность для пользователя объяснений, которые выдает система; проиворечивость и неполнота правил; согласование контекстов действия правил. По результатам 6-го этапа осуществляется модификация системы. Наиболее простым её видом явл-ся усовершенствование прототипов. Этот вид затрагивает только этапы 4 и 6. Более серьёзным видом модификации явл-ся переконструирование представлений. Этот вид модификации необходим в том случае, если обнаруживается, что желаемое поведение системы не достигнуто. Предполагается возврат на этап формализации и далее осуществляется весь цикл проектирования. Если проблемы функционирования системы еще более серьёзны, то приходится возвращаться на этапы 2 и 1 для переформулирования требований к системе и основных понятий. 3. Практические аспекты разработки и внедрения ЭС. В соответствии с результатами тестирования ЭС может находиться на одной из следующих стадий: 1) демонстрационный прототип (решает только часть задач в рамках ПО, демонстрируя правильность выбранного аппарата логического вывода). Срок доведения системы до этой стадии - около 3-х мес., кол-во правил в базе знаний - 50-100. 2) исследовательский прототип (решает все задачи в рамках ПО, на недостаточно устойчива в работе, не полностью проверена). Срок доведения - 1-2 года, кол-во правил - 200-500. 3) действующий прототип (решает стабильно все задачи в рамках ПО, но недостаточно эффективна в работе, в том числе нерациональное использование памяти, невысокое быстродействие). 2-3 г., 500-1000. 4) промышленная система (обеспчивает эффективную работу и высокое качество решений, содержит по сравнению со стадией 3 намного больше правил в базе знаний, программное обеспечение по сравнению с 3) переписано на язык низкого уровня). 2-4 г., 1000-1500. 5) коммерческая система (предполагает обобщение задач, уход от специфики ПО, предназначается для продажи другим потребителям. Развита по сравнинию с 4) система редактирования знаний, интерфейса с конкретным пользователем, обучения). 3-6 лет, 1000-3000. В процессе проектирования ЭС следует учитывать тот отрицательный опыт, который накоплен разработчиками на каждой стадии проектирования. На этапе 1 может оказаться, что система или задача настолько трудна, что её нельзя реализовать в рамках выдеенной проектировщиком системы ресурсов (время, деньги и т. д.). Проектировщики должны очень внимательно подойти к вопросу, сможет ли решение задачи принести существенную пользу, для пресонала, который её эксплуатирует. Следует учесть, что для сокращения времени проектирования нельзя расширять состав проектировщиков, так как процесс проектирования итеративный и категории проектировщиков не могут в сжатые сроки осмыслить все этапы проектирования. Традиционной ошибкой этапа 3 явл-ся подгонка инструментального средства под понятия и взаимосвязи конкретной ПО. Нельзя соглашаться при разработке прототипа на программирования сразу же на языках низкого уровня, т. е. без использования инструментальной системы. На всех стадиях проектирования инженер по знаниям работает с экспертом и при этом возникает целый ряд трудностей, которые заранее надо учитывать: эксперты всегда должны быть высококвалифицированными, их нужно заинтересовывать материально; эксперт никогда не может найти время на работу с инженером по знаниям; в системе обязательно должна использоваться та же терминология, что и у экспертов ПО; только в этом случае эксперт может успешно понимать структуру базы знаний и вносить в неё соответствующие изменения; с течением времени эксперт теряет интерес к проекту системы и постоянно сокращает время работы с проектировщиком. Для устранения этого проектировщик вносит изменения в систему только вместе с экспертом, тестирует также вместе с ним; эксперт незнаком, как правило, с компьютером, поэтому РС устанавливается на его рабочем месте и доработка системы производится там же; при извлечении знаний эксперта проектировщику очень трудно отделить знания ПО от метазнаний, поэтому работа с экспертом должна происходить не по всем вопросам в целом, а по строго спланированным инженером по знаниям порциям. На этапе 4 при разработке прототипа следует стремиться не разрабатывать самостоятельно средства объяснения, а использовать только те, что есть в инструментальной системе. При разработке первого прототипа необходимо стремиться к тому, чтобы в базу знаний попали простые универсальные правила и сокращать количество специфических правил. На этапе 6 следует учитывать, что если размер правил превышает 300, то их исправление и добавление может привести к появлению новых ошибок, поэтому должен существовать специальный тест, который проверяет систему на непротиворечивость правил. Особенности реализации экспертных систем на базе логической модели знаний. 1. Понятие логической модели знаний. 2. Характеристика языка предикатов первого порядка. Особенности представления знаний. 3. Аппарат логического вывода. 4. Особенности машинной реализации языка предикатов первого порядка. 1. Понятие логической модели знаний. В основе лог. модели знаний лежит понятие формальной теории и отношения, которые существуют между единицами знаний можно описывать только с помощью синтаксических правил, допустимых в рамках этой теории. Формальная теория задается всегда четверкой символов S=, где В - конечное множество базовых символов, иначе - алфавит теории S; F - подмножество выражений теории S, называемых формулами теории. Обычно имеется эффективная процедура, которая представляет собой совокупность правил, позволяющих из элементов множества В строить синтаксически правильные выражения. А - выделенное множество правил, называемых аксиомами теории, т. е. множество априорно истинных формул. R - конечное множество отношений { r1, r2, ... , rn } между формулами, называемыми правилами вывода. Для любого ri существует целое положительное число j, такое, что для каждого множества, состоящего из j формул, и для каждой формулы F эффективно решается вопрос о том, находятся ли эти j-формулы в отношении ri с формулой F. Если ri выполняется, то F называют непосредственным следствием F-формул по правилу ri. Следствием (выводом) формулы в теории S называется такая последовательность правил, что для любого из них представленная формула явл-ся либо аксиомой теории S, либо непосредственным следствием. Правила вывода, которые разрабатываются проектировщиками, позволдяют расширить множество формул, которые явл-ся аксиомами теории. Формальная теория наз. разрешимой, если существует эффективная процедура, позволяющая узнать для любой заданной формулы, существует ли её вывод в теории S. Формальная теория S наз. Непротиаворечивой, если не существует такой формулы А, что и А, и не А выводимы в данной теории. Наиболее распространенной формальной теорией, используемой в системах искуственного интеллекта явл-ся исчисление предикатов, то есть функций, которые могут принимать только 2 значения. К достоинствам логической модели относят: - наличие стандартной типовой процедуры логического вывода (доказательства теорем). Однако такое единообразие влечет за собой основной недостаток модели - сложность использования в процессе логического вывода эвристик, отражающих специфику ПО. К другим недостаткам логической модели относят: - “монотонность”; - “комбинаторный взрыв”; - слабость структурированности описаний. 2. Характеристика языка предикатов первого порядка. Особенности представления знаний. В основе языка предикатов первого порядка лежит понятие предикатов, то есть логическая функция от одной или нескольких нелогических пременных. Функция может принимать значения истина (t) или ложь (f). В рамках логики утверждение считается истинным, если и относящееся к нему предположение считается истинным и заключение самого утверждения тоже истина. Синтаксис языка предикатов включает: предикативные символы, символы переменных, константы (?), а также разделители ( ), [ ], “, ‘. Предикативные символы используются для обозначения отношений. Объекты отношений записываются в ( ) после предикативного символа и наз-ся аргументами. Полная запись отношения наз-ся атомной или атомарной формулой. Атомарная формула: Является ( Иванов, спец.—поЭВМ) предикативный терм 1 терм 2 символ Термы могут представляться констанатами и переменными. Разрешено также в качестве термов использовать функции, к-рые обязательно должны быть определены в рамках ПО. Проектировщик ЭС заранеее определяет, как интерпретировать порядок термов в отношении. Допустимые выражения в исчислении предикатов, в частности атомарные формулы, наз-ся правильно построенными функциями ( ППФ ). В языке предикатов для каждой ППФ обязательно определяется конкретная интерпретация. Как только для ППФ определена интерпретация, говорят, что формула имеет значение “истина”, если соответствующее утверждение ПО истинно, в противном случае ППФ имеет значение “ложь”. Из формул можно составить предложение с помощью логических связок: конъюнкция, дизъюнкция, импликация, отрицание. Конъюнкция ( ) используется для образования составных фраз: Учится ( Иванов, эк.-университет ) располагается ( эк.-университет, Киев ) ППФ, построенные с помощью связки конъюнкция, наз-ся просто конъюнкциями. Дизъюнкция ( ) реализует функцию не исключающего “или”. Находятся ( Иванов, аудит.-147) И находится ( Иванов, библиотека ). ППФ, построенные с помощью связки дизъюнкция, наз-ся дизъюнкциями. Связка импликация ( ) используется для представления утверждения типа “если, то”. Владеть ( Иванов, машина-1) марка ( машина-1, “BMW”). ППФ, построенная путем соединения формул с помощью связки импликация, наз-ся импликацией. Левая сторона импликации наз-ся антецедент, правая - конциквент. Импликация имеет значение “истина”, если антецедент и конциквент имеют значения “истина”, либо антецедент имеет значение “ложь” независимо от конциквента. В остальных случаях импликация имеет значения “ложь”. ППФ со знаком отрицания ( ~ ) пред ней наз-ся отрицанием. В языке предикатов атомная формула может принимать только истинные значения, только ложные значения, а также в зависимости от значений переменных, которые в нее входят, либо итсина, либо ложь. Для того, чтобы при исчислении предикатов можно было манипулировать значениями переменных, потребовалось ввести понятие “квантор”. Квантор - это операция, в которой участвуют все значения переменной одного предиката. Квантор служит для указания меры, в какой экземпляры переменной (?), то есть константы должны быть истинными, чтобы все значения в целом были истинными. Различают квантор общности и квантор сущестовования . Если перед предикатом записан квантор для какой-то переменной, напр. (х), то это означает, что значение предиката будет истинным только в том случае, если все значения переменной х будут истинными. (х) ( специалист-по-ЭВМ (х) программист ) Если перед предикатом записан квантор , напр. (х), то для истинности предиката достаточно, чтобы только некотрые значения переменной, по крайней мере одно, были истинными. (х) ( специалист-по-ЭВМ(х) оптимист(х) ) В рамках одного предиката можно использовать и кванторы общности, и кванторы существования, но для разных переменных.(х) (y) ( служащий (х) руководитель (y, х))
Если некотрая переменная в ППФ проквантифицирована, то она называется связанной. В противном случае переменная называется свободной. Любое выражение, которое получается путем квантифицирования правильной формулы, является также ППФ. Предикатами первого порядка наз-ся предикаты, в которых не допускается квантификация по предикатным или функциональным символам, а можно квантифицировать только переменные. 3. Аппарат логического вывода. В языке предикатов процедуры логического вывода производятся над знаниями, представленными во внутренней форме по отношению к тем описаниям, к-рые выполнил проектировщик, отражая специфику ПО, т. о. проектировщик работает с внешней формой представления знаний, а процедуры логического вывода - со внутренней. Перевод внешней формы во внутреннюю производится в системах, реализующих язык предикатов, автоматически на основе таблиц истинности для вычисления отдельных предикатов и логических операций, а также на основании целого ряда эквивалентности ( законы де Моргана, дистрибутивные законы, ассоциативные законы ). В процессе логического вывода языка предикатов используются операции, к-рые применяются к существующим ППФ с целью построения новых ППФ. “Modus ponens” - используется для создания из ППФ вида А ППФ вида В ( А В). (“турникет”) интерпретируется как “следовательно”. Операция специализации. Суть — позволяет доказать, что если некоторому классу обьектов присуще к.-л. свойство, то любой обьект данного класса будет обладать этим свойством. Для всех обьектов класса исп. свойство А, следовательно x) W(x), A L*W(A) (?) Операция — унификация. Использ-ся для док-ва теории, содержащих квантиоризированные формулы приводят в соответствие определенные подвыражения формы путем нахождения подстановок. Операция резолюция. Используется для порождения новых предположений. В основе метода резолюции лежит опровержение гипотезы и доказательство, что это неверно. В процессе реализации метода используется операция исключения высказывания, если эти высказывания в даных предположениях отрицаются, а вдругих — нет. Врезультате доказательства если опровержение ложно, формируется пустая резольвента. Для применения резолюции ППФ должны быть переведены в клаузальную форму путем упрощения, а затем представлено в форме дизьюнкции. Процесс преобразования сводится к следующ. основным этапам: 1 — исключение символов импликации из формул и ограничение области действия символа отрицания 2 — разделение переменных, т.е. замена одной связанной квантором переменной, кот. встречается в выражении несколько раз — различными именами 3 — исключение кванторов существования путем их замены функциями, аргументами которых являются переменные, связанные квантором общности, область действия кот. включает область действия исключенного квантора существования. 4 — преобразование предположений в префиксную форму, т.е. в ППФ не остается кванторов существования. Каждый квантор общности имеет свою переменную, поэтому все кванторы общности можно переместить в начало ППФ и считать, что область действия каждого квантора включает всю ППФ. 5 — приведение матрицы к коньюнктивной нормальной форме, т.е. коньюнкции конечного множества дизьюнкций. 6 — исключение кванторов общности. Это возможно, т.к. все переменные, оставшиеся на этом этапе относятся к квантору общности. 7 — исключение символов коньюнкции. В результате матрица остается только в виде дизьюнкций, над которыми возможно проведение операций резлюции. 4. Особенности машинной реализации языка предикатов первого порядка. Машинная реализация языка предиката первого порядка имеет ряд серьезных проблем, которые связаны с универсальностью аппарата логического вывода. 1-я проблема — монотонность рассуждений (в процессе логического вывода нельзя отказаться от промежуточного заключения, если становятся известными дополнительные факты, которые свидетельствуют о том, что полученные на основе этого заключения решения не приводят к желаемому результату. 2-я проблема — комбинаторный взрыв ( в процессе логического вывода невозможно применять оценочные критерии для выбора очередного правила. Безсистемное применение правил в рассчете на случайное доказательство приводит к тому, что возникает много лишних цепочек ППФ , активных в определенный момент времени. Это чаще всего приводит к переполнению рабочей памяти. В процессе исследований по отысканию эффективных процедур машинной реализации языка предиката наметилось 2 основных подхода(кон. 60-х гг.): 1 — Отбрасывается принцип универсальности языка предиката и производится поиск конкретных процедур, эффективных для конкретной предметной области. В этом случае в БЗ вводились обширные знания предметной области. Наиболее типичный представитель — LISP 2 — развивался в рамках традиционной логики и был направлен на сохранение универсальности , свойственной языку- предикату путем разработки эффективных процедур логического вывода универсальных по своему характеру, но позволяющих нейтрализовать монотонность и комбинаторный взрыв. Наиболее эффективной разработкой этого подхода явл. язык PROLOG. В нем принята обратная стратегия вывода. Полностью реализованы все средства описания знаний языка-предиката, в т.ч. и кванторами для порождения новых высказываний используется операция резолюции.В качестве процедуры поиска решения, позволяющей устранить монотонность и комбинаторный взрыв используют поиск в иерархически упорядоченном пространстве состояний. PROLOG. Реализация на ПЭВМ 1. Интегрировання Среда языка Turbo Prolog. 2. Структура программы 3. Стандартные типы доменов 4. Прототипы предиката 5. Утверждения и цели 6. Арифметические выражения. 7. Встроенные прдикаты языка 1. Интегрировання Среда языка Turbo Prolog. Функционирование Т.Р. требует наличие следующих стандартных каталогов: корневой Prolog, в котором должны находится следующие файлы: prolog.exe prolog.ovl для создания exe файла prolog.r тексты сообщения об ошибках prolog.hlp файл помощи prolog.sys конфигурация среды prolog.lib библиотеки prolog.obj вспомагательный файл для создания пользов-их exe файлов подкаталог PRO для пользовательских исходных файлов (расширение .pro) подкаталог OBJ для пользовательских обьктных и prg файлов подкаталог EXE для хранения пользовательских exe файлов подкаталог DOS для команд ОС в том случае, если предполагается их использование из пользовательских программ. (min command.com) 2. Структура программы на TURBO PROLOG 1.Domains 2.divdicates 3.clauses 1 Для определения типов доменов или данных, используемых в программе 2 описание прототипов пользовательских предикатов 3 “утверждения” включает описание фактов в виде предикатов и правил, т.е. декларативных и процедурных знаний 4 содержит цель решения задач, при его отсутствии система запрашивает цель решения задачи в окне диалога и в этом-же окне получаем ответ, при его присутствии в нем помещаем пользовательский интерфейс. Место для печатания -35--36--37- readint () (integer) : (0) - читает целое число, чтение заканчивается нажатием readreal () (real) : (0) - вещ. readchar() (char) : (0) - читает единичный символ readln () (string) : (0) - читает строку символов inkey () (char) : (0) - заканчивается истиной, если после предыдущей операции была нажата клавиша, возвращается её код. Если не была нажата, то предикат оканчивается неудачей nl - код двух клавиш - переход на новую строку write (x1, x2, ...) (переменные и константы) : (i, i, ...) - выдает на текущее устройство записи констант и содержание переменных writef (, x1, x2, ...) (string, ) : (i, i, ...) Структура формата: “ % - m.pw “, где % - признак форматного вывода если задан “-”, то знаки должны выравниваться по левому краю, если не задан - по правому m - длина поля вывода p - кол-во цифр после точки w - тип числа, вместо w записывается f, если выводится число в десятичном виде, e - в экспотенциальной форме, q - в самом коротком формате. Предикаты работы с символьными данными. str_lon (, ) (string, integer) : (i, i) (i, 0) если задано (i, i), проверяется длина строки, если (i, 0) - возвращается длина строки Преобразование типов Все предикатные преобразования действуют в обе стороны. Случай (i, i) проверяет истинность для всех типов, кроме real. Преобразование между типами string, symbol и real, integer пр-ся (?) автоматически. char_int (, ) (сhar, integer) : (i, 0) (0, i) (i, i) str_char (, ) (string, сhar) : (i, 0) (0, i) (i, i) str_int (, ) (string, real) : (i, 0) (0, i) и т. д. Работа с командами операционной системы Необходимым условием для работы с предикатами этой группы есть наличие подкаталога DOS, в котором бы был записан минимум command.com system () (string) : (i) - передает команду OS date (, , ) (integer, integer, integer) : (i, i, i) (0, 0, 0) - устанавливает, если (i, i, i), или возвращает, если (0, 0, 0) системную дату time ... - то же dir (, , ) (string, string, string) : (i, i, 0) - выдаются на экран специфицированные файлы из каталога по маршруту. Возможно выбрать из каталога имя одного файла с помощью стрелок управления курсором, при нажатии имя этого файла присваивается третьему аргументу предиката Специальные предикаты языка Turbo Prolog bouncl () - “истина, если переменная является конкретизированной free () - “истина, если переменная не является конкретизированной fail - всегда ложн. вызывает возврат для проверки базы в правилах ! - (cat) - предикат отсечения, ограничивает возврат exit - останавливает выполнение пользовательской программы и передает управление меню Turbo Prolog trace - общее включение режима отладки. Указывается в начале исходной программы trace () (symbol) : (i) (0) - устанавливает, если i, или возвращает, если 0, текущий режим отладки. В качестве статуса можно использовать on/off. Использование этого предиката предполагает наличие trace в начале программы diagnostics - позволяет выдать анализ программы в процессе компиляции. Анализ включает имена используемых предикатов. Для каждого имени определяется, являются ли аргументы конкретного предиката фактами или указывается конкретность предиката. nowarnings - отключает предупреждения в процессе компиляции project “имя файла” - данная программа является частью проекта include “имя файла” - в компиляцию включается файл с указанным именем Управление ходом выполнения программ на языке ТР. 1. Рекурсия. 2. Возврат и отсечение. 1. Рекурсия. В механизм обработки программ на языке ТР заложена рекурсия, то есть вычисление значения функции с помощью той же функции, но с измененными параметрами. Рекурсия в ТР реализуется в 2 этапа: 1) исходная задача разбивается на более мелкие частные задачи и формируются частные решения и на основе которых затем будет получено общее решение задачи. Процесс разбиения задачи на подзадачи наз-ся редукцией. Редукция завершается в том случае, если сформирована подзадача, которая может быть решена непосредственно. 2) сборка решения, начиная от самого (?) последнего к самому общему. Для использования рекурсии в программах необходимо использовать следующий формат правила рекурсии: if (1) (2) (3) (4) (5) В структуре правила компоненты (1), (3), (5) могут присутствовать или отсутствовать с учетом специфики решаемой задачи. Компоненты (2), (4) обязательны, так как они организуют аппарат активизации правила рекурсии. Обычно компонента (1) - это предикаты, которые не влияют на рекурсию. Компонента (3) содержит предикаты, с помощью которых формируются новые значения аргументов, участвующих в рекурсии, а (5) включает предикаты, которые формируют с помощью аппарата рекурсии искомые значения. (5) - сборка решения. (2) - используется для останова рекурсии, а (4) - реализует повторный вызов рекурсивного правила для новых значений аргумента. В зависимости от заданных граничных условий различают нисходящую и восходящую рекурсию. Пример. Определение n-го терма последовательности 1, 1, 2, 6, 24, ... N 0 1 2 3 4 ... 0 терм=1 3 терм=2*3 1 терм=1*1 4 терм=6*4 2 терм=1*2 5 терм=24*5 Для обозначения того факта, что n-й член последовательности равен V, вводится предикат следующего вида: posl (N, V) Фрагмент программы: domains N, V = integer divdicates posl = (N, V) clauses posl (0, 1) posl (N, V) if 1) N>0 2) M=N-1 3) posl (M, U) 4) V=U*N goal posl (3, x) Решение задачи производится в 2 этапа: I этап. 1. Производится попытка удовлетворить запрос пользователя, используя первое утверждение в разделе clauses (posl (3,x) сопоставляется с posl (0, 1)). Так как 0 не сопоставляется с 3, то попытка завершается неудачей. После этого posl (3, x) сопоставляется с заголовком 2-го утверждения posl (N, V). Отсюда N получает значение 3, а V связывается с х и система переходит к доказательству подцели в теле правила: 1) N>0 согласуется при N1=3 2) M1=N1-3 согласуется при N1=3 и M1=2 3) posl (2, U1) приводит ко второму рекурсивному обращению и так как это обращение не согласовано с первым, то последнее утверждение (V=U*N) откладывается. 2. Согласование posl (2, U1) с posl (0, 1) приводит к неудаче. Происходит сопоставление с заголовком 2-го утверждения, что заканчивается удачей, при этом N2=2 и V=U1 . происходит доказательство по цели этого утверждения: 1) согласуется при N2=2 2) согласуется при N2=2 и М2=1 3) posl (1, U2) приводит к повторному рекурсивному обращению 4) откладывается 3. Согласование posl (1, U2) с posl (0, 1) приводит к неудаче. Сопоставление с заголовком 2-го утверждения заканчивается неудачей, при N3=1 и V=U2 . Происходит доказательство по цели этого утверждения: 1) согласуется при N3=1 2) согласуется при N3=1 и М3=0 3) posl (0, N3) приводит к повторному рекурсивному обращению. Полученное целевое утверждение сопоставляется с первым целевым утверждением posl (0, 1), при этом U3 получает заначение 1. На этом этап разбиения заканчивается. II. Этап сборки решения. Производится попытка согласования самого последнего из отложенных целевых утверждений, если это удается, то производится согласование предпоследнего целевого утверждения, и так до самого первого из отложенных, то есть запроса. 1) U2=U3*1 , так как U3=1 то U2=1 2) U1=U2*2 U1=2 3) X=U1*3 X=6 2. Возврат и отсечение. В процессе реализации запроса интерпретатору языка необходимо анализировать множество фактов и правил, к-рые извлекаются в процессе нескольких просмотров соответственных баз фактов. При этом в процессе одного просмотра формируется частичное решение. Процесс в PROLOGе выполняется автоматически путем пометки или заполнения тех модулей, к-рые анализировались перед текущей целью, с тем, чтобы исключить полученное частное решение из дальнейнего рассмотрения. Этот механизм в PROLOGе наз-ся возвратом и реализуется через использование стандартного предиката fail, к-рый всегда имеет значение “ложь”. Этот предикат заставляет интерпретатор проанализировать ещё раз базу фактов, чтобы выполнить более целевое утверждение для других значений переменных. Он позволяет получить в базе все возможные решения. ПРИМЕР: domains p,T=symbo L divdicat s like (P,T) poleg (T) dauses like (“Иванов”,” пиво”). like (“Иванов”,” сок”). poleg(“cok”)... otv if like (P,T) and poleg (T),nl, write (P), fail. goal otv. Для управления процессом выполнения программ в PROLOG имеется встроенный предикей cut, кот. кодируется в turbo-PROLOG как !. Основное назначение — остановка процесса возврата, т.е. приостановка выработки дальнейших решений. Этот процесс в Прологе наз. ОТСЕЧЕНИЕМ. Чаще всего предикей cut используется совместно с fail. ПРИМЕР … goal like (P,T) T= “кефир”, nl, write ( “любитель кефира найден”) !. fail Отсечение используется для устранения бесконечных циклов (см. пред. пример): clauses posl (0,1) if ! posl(N,V) if M=N-1 posl (M,U) V=U*N Отсечение также используется для устр. взаимоисключающих утверждений. ПРИМЕР ball (M,’A”) if M> so,! ball(M, “B”) if M< so an M>60,!. ТЕМА: АГРЕГАТЫ ФАКТОВ 1.Списки 2.Динамическая база фактов 3.Структуры 1. Списки. Если в пр-ме необходимо организовать с переменными или заранее неопределенным количеством объектов, то испол. списки. СПИСОК — упорядоченная последовательность эл-в одного типа неопределенной длины, кот м. состоять из 0 и более эл-в. Константы ,попавшие в список , записываются в [ ] и отделяются друг от друга запятыми. Исходя из определения списка, два списка , сост. из одних и тех же эл-в , но расположенных в разном порядке считаются разными. В разделе domains эл-ты списка обяз-но д.б. сопоставлены с определенным типом домена (Sp=integer*). Список в domains м.б. опосредствован через имя переменной, эл-ты кот. собираются в список.domains
k_fms = string, kol = integer, Sp = kol* divdicates fms ( k_fms, kd, ...) Списки состоят из заголовка ( начала списка) и захвата (окончания списка). К заголовку относится только 1-й эл-т списка, остальное — хвост. Список с нулевым количеством эл-в определяется как пустой список, он не имеет ни заголовка ни хвоста. Для работы со списками в языке имеется ряд встроенных предикатов. MEMO (, ) — где м.б. задан либо именем Sp, либо непосредственно константами, входящими в этот список. Предикат определяет принадлежность эл-та к списку. I — деление списка на голову и хвост [ Head I Tail] или [H I T] H — или переменной для обозначения заголовка T — — “ — хвоста ПРИМЕР domains list=char* divdicates test (List) clouses test ( [‘A’, ‘B’ , ‘C’, ‘D’] ). goal test ([H/T]), nl, write (H) APPEND ( [ эл-ты старого списка ],[ эл-ты нового списка ],< имя нового списка > ) — из 2-х списков, старого и нового, создают III список. REVERS ( [ эл-ты стар. списка], < имя нового списка > ) — меняет последовательность эл-в на противоположную FINDALL (< имя переменной >,< формат предиката >,< имя списка >) ПРИМЕР domains post = string Kol, Cena, Sum = integer Sp = integer* ( Sp = Kol*) Kod = string divdicates tmc ( P, Kol, Cena) sum ( Sp, Sum) goal write ( “ Введите код”), readln ( Kod), nl, findall ( Kol, tmc ( Pos1, Kod, Kol, Cena), Sp), sum (Sp, Sum), write ( “Количество =” , Sum) clauses tmc ( “ 001”, “001”, 45, 80) … sum ( [ ], 0). sum ( [ H/T ], Sum) if sum ( T, Sum1). Sum = H + Sum1. В языке имеется возможность работы с динамической базой фактов, в которой м. объединяться как однородные, так и разнородные предикаты-факторы. База фактов — нечто среднее м-у реляционной СУБД и массивом. В момент активизации все факты базы переносятся в ОЗУ с внешнего зап. устройства. Для работы с БД создается новый раздел программы, в кот. определяются прототипы предикатов-фактов, объедененных в базу. DATABASE прототипы в этом разделе описываются по тем же правилам, что и в divdicates. Раздел database записывается перед разделом divdicates и предикаты, кот. в нем описываются не могут описываться в разделе divdicates, а ис-ся в разделах clouses и goal. Активизация базы происходит в области ОЗУ, кот. по умолчанию имеет тип домена dbasedom. Этот тип программист не указывает явно в программе в разделе domains, но м. его использовать в качестве аргументов встроенных предикатов языка, что позволяет сократить текст программы при работе с базой. domains dbasedom = tms(Post, Kod, Kol, Cena) … database … tmc (Post, Kod, Kol, Cena) Возможно дополнение базы новыми фактами, удаление устаревших, корректировка отдельных фактов. Все операции в базе фактов производятся с помощью стандартных встроенных предикатов: asserta ( < факт >) ( dbasedom) : (i) assertz — используется для добавления нового факта в базу. Факт д.б. обязательно определен и относится к области dbasedom. При использовании предиката asserta факт добавляется перед остальными фактами имеющегося предиката. assertz — добавление после — “ — retraсt(< факт>)( dbasedom) : (i) — удаление из БД первого факта, кот. сопоставляется с указанным в retraсt фактом. Возможно удаление группы. При этом в факте указывается общее для удаления фактов значение, а на месте всех остальных переменных записываются те переменные, кот. нет в этом предикате. SAVE(< имя файла >) — сокращает все факты дин. базы из ОЗУ на магн. диск под именем string : (i) заданным в предикате save/ CONSULT(< имя файла >) — добавляет в опер. дин. базу все факты из файла на диске сstring : (i)указанным именем. 2. Приемы работы с динамической базой фактов. 1.Перезапись фактов из раздела clouses в базу на МД. domains Post, Kod = string Kol, Cena = integer database tmc ( Post, Kod, Kol, Cena) divdicates perezap dauses tmc (“001”, “001”, 45,80). … perzap if save (“data”) gocel perezap. 2. Создание базы в процессе диалога domains Post, Kod = string Kol, Cena = integer Pc = integer&&признак окончания ввода database tmc ( Post, Kod, Kol, Cena)&&база создается первоначально divdicates vvod clouses vvod if write (“Введите код поставщика”), nl, readln (post), nl, write (“Введите код ТМЦ”), nl, readln (Kod), nl,write (“Введите кол-во ТМЦ”), nl, readint (Kol), write (“Введите цену”), nl, readint (Cena), assertz (tmc ( Post, Kod, Kol, Cena)), write ( “ Введите признак продолжения s/0”), pr=0, vvod. goal vvod, save (“data”) 3.Дополнение базы новыми фактами … goal consult(“data”), vvod, save(“data’). 4.Активизация фактов из файла на диск domaines Post, Kod = string Kol, Cena = integer Sum, Sum1 = integer Sp = kol* database tmc (Post, Kod, Kol, Cena) divdicates sum( Sp, Sum) clouses sum ( [ ], 0). sum ( [ H/t ], Sum) if sum(T,Sum1), Sum= H + Sum1. goal consult (“data”), write (“Введите код ТМЦ”), nl, readln (Kod), sum(Sp, Sum), write (Sum). 5.Удаление конкретных фактов из БД domains Post, Kod = string Kol, Cena = integer database tmc (Post, Kod, Kol, Cena) divdicates udal clouses udal if write (“Укажите код поставщика”), nl, readln (Post), write (“Укажите код ТМЦ”), nl, readln (Kod), retract (tmc (Post, Kod, Kol, Cena)), goal consult (data), udal, save(“data’). 6.Удаление группы факторов dauses udal if write (“Введите код поставщика”), nl, readln (post), retract(tmc (Post, Kod, Kol, Cena)), … С помощью retract производится удаление дин. базы фактов из ОЗУ. Корректировка содержимого факта. Операции проихзводятся в 2-а этапа: 1-- с помощью retract осущ. удаление устаревшего факта из базы 2-- assertz — добавление нового факта в базу. 3. Структуры. СТР-РА — набор объектов, логически связанных между собой в процессе решения задачи и объединенных под одним именем. Стр-ра в П. используется при создании сложной базы фактов и правил. Если объекты стр-ры относятся к одному типу доменов. то стр-ра наз. однодоменной. Допускается исп-е доменов разного типа, в этом случае стр-ра наз. разнодоменной. Исп-е стр-ры в программах позволяет упорядочить базу, разрешается обращение к стр-рам по имени. ТЕМА: Организация работы с файлами в системе “ ТУРБО-ПРОЛОГ”. 1. Определение файлов. 2. Порядок работы с файлами пользователя в программе. 3.Стандартные предикаты обработки файлов и техника их использования. 1. Определение файлов. В П. используются традиционное для других языков программирования определение файла. Для указания порядка работы с конкретными файлами в пр-ме, исп-ся символическое имя файла. В системе приняты след. станд. имена файлов, с кот. м. работать в программах без предв. описания. 1.Входной с экрана дисплея keyboard 2.Выходная форма на экран screen 3.Вых. ф-ма на устройство печати printer 4. — “ — на порт com1 По умолчанию наз-ся файлы (1) и (2). Для переопределения стандартных файлов и файлов пользователя исп-ся станд. предикаты readdevice (< символьное имя файла>) (file):(i) writedevice ПРИМЕР readdevice (printer), write (“Работа завершена”), readdevice (screen), ... Файлы пользователя в П. м. представлять собой как Д. так и факты в виде предикатов, при этом 1-я запись файла д. соответствовать 1-му предикату-факту. 2. Порядок работы с файлами пользователя в программах следующие: 1.Определение символьного имени файла 2.Открытие соответствующего вида доступа 3.Определение или переопределение уст-ва, используемого для обработки файла 4.Закрытие файла после обработки с возможным переопределением устройств ввода-вывода Для определения символьного имени в П. используется стандартный домен file, определенный в разделе domaines. Символьное имя м. совпадать, а м. не совпадать с его именем в ОС. Символьное имя действует также в пределах той пр-мы, кот. его описывает. В зависимости от порядка работы с файлом, его открытие м производиться с помощью след. стан. предикатов: OPENWRITE( < сим. имя файла>, < имя файла в ОС>) ( file, string):( i,i) — открывает файл с указаным именем для операции записи. Если этот файл реально существует под указаным именем в среде ОС, то он уничтожается. OPENREAD( < сим. имя файла >,< имя файла в ОС >) ( file, string):( i,i) — открывает файл с указаным именем для чтения OPENAPPEND ()( file, string):( i,i) — открывает файл для дозаписи. Если при использовании предиката OPENREAD и OPENAPPEND файл не найден, то это интерпр. как ошибка. Если при использовании предикатов OPENWRITE и OPENMOCLIFY файл не найден, то происходит создание нового файла. Для проверки наличия файла в П. имеется след. стан. предикат: EXISTEFILE() ( string):( i) Если файл с указанным именем не сущ., то предикат принимает значение .t., если нет- ложь. Переопределение устройств для работы с файлами пользователя производится с помощью readdevice и writedevice FILE_STR (< имя файла в ОС>,< строка>) (string , string) : (i,0) ( i,i) — читает знаки до 64кб из файла в перем. памяти, если задано (i,0). Если задано ( i,i), то знаки из пер.памяти зап-ся в файл. Чтение и запись прекращается , если встретиться признак конца файла. Этот предикат работает без определения символьного имени файла. READTERM (,< терм>) (< имя области>,< терм>) : (i,0) После открытия файла этот предикат читает факты из него. Первый аргумент предиката д.б. описан в разделе domains программы EOF (< символьное имя файла>) (file) : (i) Предикат имеет значение “ Истина”, если указатель файлов позиции установлен на конце файла FILEPOS (< сим. имя файла>,< позиция>,< режим>) (file,real, integer) : (i,i,i) (i,0,i) RENAME (< имя файла1 в ОС>,< имя файла2 в ОС>) — переим. файла (string,string) : (i,i) DELETE (< имя файла в ОС>) — удаление файла (string) : (i) DISK (< маршрут>) (string) : (i) (0) — устанавливает ,если (1) или возвращает, если задана (0) дисковод или тех. каталог, подкаталог... CLOSEFILE (< сим. имя файла>) (file) : (i) 3. Стандартные предикаты обработки файлов и техника их использования. Техника работы с файлами в программах 1.Создание файла domains file = ff P2 = integer Pole, Pole1 = string divdicates vvod put clouses put if write (“Введите признак продолжения”), readint (Pr), Pr=0 vvod vvod if write (“Введите строку”), readln (Pole), nl, write (Pole), concat (Pole, “ n”, Pole1), openappend (ff, “text”) writedevice (ff), write (pole1), closefile (ff), writedevice (screen), write ( “Строка”, Pole1, “на диск записана”) В поле м.б. введенозначение предиката-факта, с кот. в дальнейшем м. работать как ср-вами обработки файла, так и ср-вами динам. фаз фактов. Предположим,что в этом примере пользователь ввел значение предиката-факта tmc tmc ( Post, Kod, Kol, Cena) 2.Обработка фактов из файла domains file = ff data= tmc ( Post, Kod, Kol, Cena) Post,Kod=string Kol, Cena=integer divdicates put spr clouses put if not (eof (ff)), spr. put if eof(ff),nl, write (“Работа закончена”), closefile (ff) spr if readterm (data, tmc (Post, Kod, Kol, Cena), nl, write (post), nl, put. goal openread (ff, “text”), readdevice (ff), spr. 3.Модификация данных файла domains file=ff Pr= integer Pole, Pole1 = string K = real divdicaes put mod clouses put if write ( “Введите признак продолжения”), readint (P2), p2 = 0, mod. mod if write (“Введите номер записи”), nl, readreal (K), nl, K1=K*12, openmodify (ff, “text”), readdevice (ff), 48 filepos (ff,K1,0) readln (Pole), write ( “Старое значение”, pole), nl, writedevice (ff), filepos (ff,K1,0), write (Pole1,”n”), closefile (ff), writedevice (screen), write ( “Новое значение”, Pole1), nl, readdevice (keybord), put goal mod ТЕМА: Средства модульного прг-я в ТП ТП, являясь прообразом языка парал. вычислений, поддерживает стиль модульного проектирования. Средства ТП для поддержки мод. прог-я следующие: 1.Междумольная информационная связь в П. реализуется кака и в других языках прог-я, через общие переменные. Для этого в связываемых модулях после раздела domains, где описываются те приемы, кот. описываются в разных модулях. 2.Актуализация каждого модуля производится путем вызова соответствующего правила, кот. д.б. известно во всех связывающих модулях в разделе global divdicates. 3.Ср-ва обр-ки модульных программ. 3.1.Использование предиката include “ имя программного файла”. include — используется в том случае, когда к текущей программе на уровне исходного модуля. Цепочка модулей м.б. сколь угодно длинной, но не д.б. циклов. “ имя прогр. файла “ м. содержать маршрут поиска файла на диске. 4.project “имя файла-проекта” Эта дирректива д.б. записана 1-й в тех модулях, кот. необходимо объединить в 1-й загрузочный модуль с именем файла-проекта. По аналогам с разработками Borland, все модули, объед. в проект, компилируется отдельно, а связь происходит на уровне объектных модулей. ТЕМА: Фреймовые модели представления знаний 1.Особенности представления знаний с помощью фреймов 2.Аппарат логического вывода фреймовой модели 3.Примеры-приложения фреймовой модели 1. Особенности представления знаний с помощью фреймов Представление знаний с помощью фреймов явл. альтернативным по отнош. к системам продукции и лог. моделям. Оно дает возможность хранить родовидовую иерархию в явной форме. Фрейм — составная структурная единица, предназначенная для описания относящихся к стериотипной ситуации на объекте Осн. элемент единиц фрейма явл. слот, кот. исп. для хранения единичного знания. Станд. стр-ра слота след.: { имя слота; ;... ; ....} fi — имя атрибута, характерного для слота Si — значение атрибута qi — ссылки на другие слоты или фреймы Стр-ра слота след-я: имя файла имя слота1 значение слота1 имя слота n значение слота n Если стр-ра знаний позволяет, то при описании нужно исп-ть простые слоты, т.е. слоты, кот. имеют одно значение. Значением слота м.б. не т. константа или ссылка на др. фрейм , но и функция, кот. требует определенной детализации в процессе решения. Т. функции получили название фасет . Фреймы-прототипы — это готов. стр-ры для описания законов опр. п/о. В них отсутствуют конкр. значения слотов. При заполнении слотов конкр. значениями, они превращаются в конкретные фреймы. Часто в системах фреймы исп-ся для стереотипных послед-й действий и тогда они наз. сушариями. При заполнении фреймов -прототипов, часть слотов м. оставаться пустой фреймовой стр-ры дают воз-ть описывать объекты разного уровня иерархии, кот. явл. ключевым понятием. Иерархия объектов реализуется через аппарат исследования свойств, когда классы объектов определенного уровня наследуют строения классов фреймов более высокого уровня. Если объект, кот. описывается некоторой группой фреймов находится в концептуальной связи с верхним и нижним уровнями фреймов, то соотв. ему фреймы конструируются с учетоми иерархических отношений и при этом наследование свойств осущ. через слоты или фреймы с одинаковым именем. 2. Аппарат логического вывода фреймовой модели Логический вывод во фреймовой системе осущ. путем обмена сообщениями между фреймами разного уровня иерархии, вначале получает управление корневой фрейм, далее динам. формируется необходимая для реализации запросов цепочка фреймов след. уровня иерархии. Т.о. во фреймовой системе каждому из фреймов задается строго опр-е. Основной операцией при работе с фреймами явл. поиск по образцу. В рамках фреймовой модели образец — это фрейм, в кот. заполнены не все стр. ед-цы, а т. те, кот. б. использованы в качестве ключа для реализации действий в конкр. фреймах. Используются спец. процедуры наполнения слотов спец. значениями, а т. введение в систему новых фреймов-прототипов и новых связей между ними. 3. Примеры-приложения фреймовой модели В наст. время фреймовая модель явл. основой всех объектно-ориентированных систем прог-я. В качестве наиболее популярных приложений м. назвать языки FRL,KRL, FSM, Small Talk, а также дополнения к процедурным языкам: C++, Delphi и т.д. FRL Реализован на базе языка LISP. Каждый фрейм предст. собой станд. стр-ру с мах степенью вложенности