Методичка на тему Теория алгоритмов
Работа добавлена на сайт bukvasha.net: 2014-12-18Поможем написать учебную работу
Если у вас возникли сложности с курсовой, контрольной, дипломной, рефератом, отчетом по практике, научно-исследовательской и любой другой работой - мы готовы помочь.

Предоплата всего
от 25%

Подписываем
договор
Кафедра: Автоматика и информационные технологии
ТЕОРИЯ АЛГОРИТМОВ
Екатеринбург
2006
Приводится формализация понятия «алгоритм». Обсуждаются два способа формального описания алгоритма –с помощью нормальных алгоритмов Маркова и через машины Тьюринга. Приводятся меры сложности алгоритмов, определяются легко и трудноразрешимые задачи, классы задач P и NP, алгоритмически неразрешимые проблемы.
Содержание
ФОPМАЛИЗАЦИЯ ПОНЯТИЯ АЛГОPИТМА
Определение
Нормальный алгоритм Маркова
Тезис Маркова
Машина Тьюринга
Основная гипотеза теории алгоритмов (тезис Чёрча)
Универсальная машина Тьюринга
МЕPЫ СЛОЖНОСТИ АЛГОPИТМОВ
Оценка алгоритма
Практические и NP-полные алгоритмы
Алгоритмически неразрешимые проблемы
«Формализация понятия алгоритма; Машина Тьюринга. Тезис Черча; Алгоритмически неразрешимые проблемы. Меры сложности алгоритмов. Легко и трудноразрешимые задачи. Классы задач P и NP. NP – полные задачи. Понятие сложности вычислений; эффективные алгоритмы.» ( из стандарта специальности ВМКСС, дисциплина «Математическая логика и теория алгоритмов)
Индивидуальная задача получается из массовой, если всем параметрам массовой задачи присвоить конкретные (допустимые) значения.
Под алгоритмом принято понимать конечную последовательность операций, называемых элементарными, исполнение которой приводит к решению любой задачи из заданного множества задач. В это определение входят такие свойства алгоритма, как дискретность, конечность (конечное число выполняемых операций), массовость (решается не единственная задача, а их класс), результативность (в результате получаем решение задачи). Кроме того, должно выполнятся ещё одно необходимое свойство алгоритма – детерминизм, которое определяется как однозначное понимание каждой операции, или, что то же самое, независимость результата выполнения каждой элементарной операции от того, кто её выполняет.
Под это определение подходит широкий круг алгоритмов. Это может быть алгоритм вычисления математической функции, алгоритм технологического процесса, алгоритм проектирования ЭВМ или цеха завода и т.д. Элементарные операции могут быть достаточно сложными: при вычислении функции это может быть, например, нахождение корней уравнения, в проектных или технологических алгоритмах – принятие сложных проектных или технологических решений.
Данное выше определение алгоритма не является формализованным и строгим по двум причинам. Во-первых, в нём не формализовано понятие элементарной операции, и, во-вторых, не формализовано представление последовательности операций. Важность разработки общего для всех алгоритмов формального описания заключается в том, что оно даёт возможность иметь общие инструментарии для сравнения, оценки, преобразования и других действий над алгоритмами.
Формализация операций алгоритмов связано со следующим. Любой алгоритм определён для некоторого объекта действия, каждый объект представляется в виде описания, причём описанием может быть не только тексты на языке, но и рисунки, чертежи и т.п. Значит, можно предположить, что объект описан в виде слова в заданном алфавите.
Объект может находиться в различных состояниях, чему соответствуют различные слова. Так, объектом для математических алгоритмов являются математическое описание задачи в форме матриц коэффициентов, графа смежности и т.п.т., для проектных алгоритмов – проектируемый объект в виде технического задания на проектирование или перечень требований и условий к результату.
Операция определяется над описанием объекта и её результатом является новое (изменённое) описание (новое слово). Например, если решается графовая задача, то результатом операции может быть описание графа с промежуточным взвешиванием рёбер и/или вершин. Результатом проектной операции будет более полное, уточнённое описание объекта.
Результатом работы всего алгоритма в графовой задаче может быть выделенный путь или цепь, частичный подграф или веса вершин или ребер. Результатом работы алгоритма проектирования является описание объекта проектирования, достаточное для его изготовления в заданной технологической базе.
Рассмотрим несколько способов формального описания алгоритмов.
Алгоритм задают в виде системы подстановок, реализующих отображение слов pi в слова qi.
pi ® qi=1,…,k.
Порядок подстановок зафиксирован. Объектом i-й элементарной операции алгоритма является слово в алфавите A, операция состоит в нахождении в этом слове первого слева вхождения слова pi и замене его на qi. Результатом операции будет изменённое слова, если вхождение найдено, или входное слово, если не найдено.Факт замены фиксируется и используется в организации следования операций.
Исходное задание представляется некоторым словом в алфавите A. Это слово является входным для первой операции, если замена произошла, то снова выполняется первая операция, если нет, то выполняется следующая операция. После каждой операции выполняется следующая операция, если замена произошла, иначе переходят к выполнению первой операции.
Алгоритм удобно представить в виде ориентированного графа, вершинами которого являются элементарные операторы и распознаватели.
Распознаватель проверяет условие – имеет ли место вхождение рi во входное слово p. Если ДА, то за ним следует оператор, который заменяет первое слева вхождение слова рi на слово qi. Если НЕТ, то управление передается на вход следующего распознавателя.
Дуги, исходящие из операторных вершин, подсоединяются либо к первой вершине – распознавателю, либо к выходной вершине. В первом случае подстановка называется обычной, во втором – заключительной.
Кроме того, имеются входная и выходная вершины. Входная вершина связана дугой с первым распознавателем.
На вход графа подается некоторое входное слово p.
Пример. Граф для трех подстановок (к = 3) (рис.1) имеет три распознавателя (РВ1,РВ2,РВ3) и три операторные вершины (ОП1,ОП2,ОП3).
Если подстановки заданы как ba ® ab, bc ® ba, bb ® ac, а входное слово
р = bcbaab, то работа алгоритма будет иметь следующий вид.
SHAPE \* MERGEFORMAT
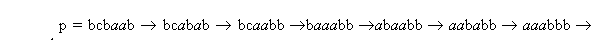

Пpимеp. Задан алфавит А={+, 1} и система подстановок:
‘1+1’ ® ‘11’ , ‘1’®`1`.
Обычная Заключительная
подстановка подстановка
Пусть дано входное слово р = ’11+11+1’ . Оно перерабатывается алгоритмом в строку:
‘11+11+1’ ® ‘1111+1’ ® ‘11111’ ® `11111` !
Алгоритм реализует сложение единиц.
Все известные до сих пор алгоритмы нормализуемы.
Машина Тьюринга состоит из следующих частей:
1. Информационной ленты, представляющей бесконечную память машины. Это бесконечная лента, разделенная на ячейки. В каждой ячейке можно поместить лишь один символ из возможного их множества S={S1,S2,….,Sm},которое составляет внешний алфавит МТ. В этом алфавите один из символов (пусть это будет S1) соответствует пустому символу.
2. Считывающей головки – чувствительного специального элемента, способного обозревать содержимое ячеек. Лента может перемещаться вдоль головки так, что в каждый момент времени головка обозревает одну ячейку.
3. Управляющего устройства (УУ), которое в каждый момент времени находится в некотором состоянии. Число состояний конечно. Обозначим множество состояний как {q1,q2,…,qn}. Среди состояний одно соответствует заключительному, при котором МТ останавливается. УУ связано со считывающей головкой.
Кроме того, УУ вырабатывает три команды на перемещение ленты: П, Л, Н, где
П – переместиться на соседнюю справа ячейку;
Л – переместиться соседнюю слева ячейку;
Н – продолжать обозревать ту же ячейку.
Совокупность символов {q1,q2,…,qn} и {П,Л,Н} образуют внутренний алфавит МТ.
Работа машины происходит в дискретном времени. В начальный момент времени в ограниченный участок ленты записано слово в алфавите S, представляющее исходное условие задачи. В остальных ячейках предполагается записанным пустой символ. Управляющее устройство находится в начальном состоянии q1. На каждом шаге работы МТ обозревает на ленте символ Sk и в зависимости от него и от состояния qi, переходит в состояние qj, заменяет Sk на символ Sl и передвигает ленту (либо нет) на одну ячейку.
Каждая элементарная операция имеет вид
qiSk ® qjSl П(Л,Н).
Множество элементарных операций упорядочено и образует абстрактную программу, которая представляет алгоритм.
Считывающая головка и управляющее устройство образуют логический блок, который представляет собой (2,3)-полюсник.
SHAPE \* MERGEFORMAT
Структура МТ имеет следующий вид:

Q - ячейка хранит символ состояния, а Р - ячейка – символ сдвига. В них происходит задержка данных символов до начала следующего такта.
В качестве начальной информации на ленту можно записать любую конечную последовательность символов (входное слово) U внешнего алфавита. В начале работы алгоритма устройство управления находится в начальном состоянии, головка обозревает первый слева непустой символ входного слова U. Если после конечного числа тактов МТ останавливается, переходя в заключительное состояние, а на ленте оказывается информация B, то говорят, что машина применима к последовательности U и перерабатывает ее в последовательность B.
Если остановка и сигнал об остановке никогда не поступают, то говорят, что МТ не применима к последовательности U.
Рассмотрим функционирование МТ на примере сложения двух чисел, которые будем изображать в виде набора единиц.
Внешний алфавит будет состоять из символов: {1, +, Ù}, где Ù – пустой символ.
Внутренний алфавит будет состоять из четырех символов {q1, q2, q3, !}, где символ q1 означает начальное состояние, а ! – заключительное состояние.
Пусть на ленте записана начальная информация:
МТ должна ее переработать в результирующую информацию:
Абстрактная программа, реализующий операцию сложения, будет иметь вид:
Начальное состояние УУ=q1, состояние ленты имеет вид:

 После первого шага состояние YY=q3, состояние ленты как на рис.
После первого шага состояние YY=q3, состояние ленты как на рис.
После пятого шага YY перейдёт в состояние q2. Состояние ленты показано на рис.
После десятого шага YY в состоянии q1 (рис. )
Последовательность команд, реализующих операцию сложения, удобно задать таблицей, которую называют функциональной схемой алгоритма.
Обоснование гипотезы.
Речь не идет о доказательстве гипотезы, так как она содержит не формализованные математические понятия.
Уверенность в справедливости гипотезы основана, главным образом, на опыте. Все известные к настоящему времени алгоритмы могут быть заданы посредством тьюринговых функциональных схем. Кроме того, внутри самой теории алгоритмов основная гипотеза не применяется, то есть при доказательстве теорем этой теории ссылок на основную гипотезу не делается.
ТЕОРИЯ АЛГОРИТМОВ
Екатеринбург
2006
Приводится формализация понятия «алгоритм». Обсуждаются два способа формального описания алгоритма –с помощью нормальных алгоритмов Маркова и через машины Тьюринга. Приводятся меры сложности алгоритмов, определяются легко и трудноразрешимые задачи, классы задач P и NP, алгоритмически неразрешимые проблемы.
Содержание
ФОPМАЛИЗАЦИЯ ПОНЯТИЯ АЛГОPИТМА
Определение
Нормальный алгоритм Маркова
Тезис Маркова
Машина Тьюринга
Основная гипотеза теории алгоритмов (тезис Чёрча)
Универсальная машина Тьюринга
МЕPЫ СЛОЖНОСТИ АЛГОPИТМОВ
Оценка алгоритма
Практические и NP-полные алгоритмы
Алгоритмически неразрешимые проблемы
«Формализация понятия алгоритма; Машина Тьюринга. Тезис Черча; Алгоритмически неразрешимые проблемы. Меры сложности алгоритмов. Легко и трудноразрешимые задачи. Классы задач P и NP. NP – полные задачи. Понятие сложности вычислений; эффективные алгоритмы.» ( из стандарта специальности ВМКСС, дисциплина «Математическая логика и теория алгоритмов)
ФОPМАЛИЗАЦИЯ ПОНЯТИЯ АЛГОPИТМА
Определение
Задача (массовая задача) - некоторый общий вопрос, на который следует дать ответ. Обычно задача содержит несколько параметров, или свободных переменных, конкретные значения которых не определены. Задача определяется 1) общим списком параметров, 2) формулировкой тех свойств, которым должен удовлетворять ответ (решение задачи).Индивидуальная задача получается из массовой, если всем параметрам массовой задачи присвоить конкретные (допустимые) значения.
Под алгоритмом принято понимать конечную последовательность операций, называемых элементарными, исполнение которой приводит к решению любой задачи из заданного множества задач. В это определение входят такие свойства алгоритма, как дискретность, конечность (конечное число выполняемых операций), массовость (решается не единственная задача, а их класс), результативность (в результате получаем решение задачи). Кроме того, должно выполнятся ещё одно необходимое свойство алгоритма – детерминизм, которое определяется как однозначное понимание каждой операции, или, что то же самое, независимость результата выполнения каждой элементарной операции от того, кто её выполняет.
Под это определение подходит широкий круг алгоритмов. Это может быть алгоритм вычисления математической функции, алгоритм технологического процесса, алгоритм проектирования ЭВМ или цеха завода и т.д. Элементарные операции могут быть достаточно сложными: при вычислении функции это может быть, например, нахождение корней уравнения, в проектных или технологических алгоритмах – принятие сложных проектных или технологических решений.
Данное выше определение алгоритма не является формализованным и строгим по двум причинам. Во-первых, в нём не формализовано понятие элементарной операции, и, во-вторых, не формализовано представление последовательности операций. Важность разработки общего для всех алгоритмов формального описания заключается в том, что оно даёт возможность иметь общие инструментарии для сравнения, оценки, преобразования и других действий над алгоритмами.
Формализация операций алгоритмов связано со следующим. Любой алгоритм определён для некоторого объекта действия, каждый объект представляется в виде описания, причём описанием может быть не только тексты на языке, но и рисунки, чертежи и т.п. Значит, можно предположить, что объект описан в виде слова в заданном алфавите.
Объект может находиться в различных состояниях, чему соответствуют различные слова. Так, объектом для математических алгоритмов являются математическое описание задачи в форме матриц коэффициентов, графа смежности и т.п.т., для проектных алгоритмов – проектируемый объект в виде технического задания на проектирование или перечень требований и условий к результату.
Операция определяется над описанием объекта и её результатом является новое (изменённое) описание (новое слово). Например, если решается графовая задача, то результатом операции может быть описание графа с промежуточным взвешиванием рёбер и/или вершин. Результатом проектной операции будет более полное, уточнённое описание объекта.
Результатом работы всего алгоритма в графовой задаче может быть выделенный путь или цепь, частичный подграф или веса вершин или ребер. Результатом работы алгоритма проектирования является описание объекта проектирования, достаточное для его изготовления в заданной технологической базе.
Рассмотрим несколько способов формального описания алгоритмов.
Нормальный алгоритм Маркова
Алгоритмическая система, созданная А.А.Марковым, основана на соответствии между словами в абстрактном алфавите A.Алгоритм задают в виде системы подстановок, реализующих отображение слов pi в слова qi.
pi ® qi=1,…,k.
Порядок подстановок зафиксирован. Объектом i-й элементарной операции алгоритма является слово в алфавите A, операция состоит в нахождении в этом слове первого слева вхождения слова pi и замене его на qi. Результатом операции будет изменённое слова, если вхождение найдено, или входное слово, если не найдено.Факт замены фиксируется и используется в организации следования операций.
Исходное задание представляется некоторым словом в алфавите A. Это слово является входным для первой операции, если замена произошла, то снова выполняется первая операция, если нет, то выполняется следующая операция. После каждой операции выполняется следующая операция, если замена произошла, иначе переходят к выполнению первой операции.
Алгоритм удобно представить в виде ориентированного графа, вершинами которого являются элементарные операторы и распознаватели.
Распознаватель проверяет условие – имеет ли место вхождение рi во входное слово p. Если ДА, то за ним следует оператор, который заменяет первое слева вхождение слова рi на слово qi. Если НЕТ, то управление передается на вход следующего распознавателя.
Дуги, исходящие из операторных вершин, подсоединяются либо к первой вершине – распознавателю, либо к выходной вершине. В первом случае подстановка называется обычной, во втором – заключительной.
Кроме того, имеются входная и выходная вершины. Входная вершина связана дугой с первым распознавателем.
На вход графа подается некоторое входное слово p.
Пример. Граф для трех подстановок (к = 3) (рис.1) имеет три распознавателя (РВ1,РВ2,РВ3) и три операторные вершины (ОП1,ОП2,ОП3).
Если подстановки заданы как ba ® ab, bc ® ba, bb ® ac, а входное слово
р = bcbaab, то работа алгоритма будет иметь следующий вид.
SHAPE \* MERGEFORMAT
| р = bcbaab ® bcabab ® bcaabb ®baaabb ®abaabb ® aababb ® aaabbb ® aaaacb. |
| + |
| + |
| РВ1 |
| РВ2 |
| РВ3 |
| ОП3 |
| + |
| ОП2 |
| q |
| - |
| - |
| |
| р |
| ОП1 |
Пpимеp. Задан алфавит А={+, 1} и система подстановок:
‘1+
Обычная Заключительная
подстановка подстановка
Пусть дано входное слово р = ’11+11+
‘11+11+1’ ® ‘1111+1’ ® ‘11111’ ® `11111` !
Алгоритм реализует сложение единиц.
Тезис Маркова
Для любого алгоритма в произвольном конечном алфавите А можно построить эквивалентный ему нормальный алгоритм.Все известные до сих пор алгоритмы нормализуемы.
Машина Тьюринга
Одно из уточнений понятий алгоритма было дано Э. Постом и А. Тьюрингом независимо друг от друга в 1936-1937гг. Основная мысль их заключалась в том, что алгоритмические процессы – это процессы, которые может свершить подходящим образом устроенная ”машина”. Ими были описаны гипотетические (условные) устройства, которые получили название «Машина Поста» и «Машина Тьюринга»(МТ). Так как в них много общего, то рассмотрим только машину Тьюринга.Машина Тьюринга состоит из следующих частей:
1. Информационной ленты, представляющей бесконечную память машины. Это бесконечная лента, разделенная на ячейки. В каждой ячейке можно поместить лишь один символ из возможного их множества S={S1,S2,….,Sm},которое составляет внешний алфавит МТ. В этом алфавите один из символов (пусть это будет S1) соответствует пустому символу.
2. Считывающей головки – чувствительного специального элемента, способного обозревать содержимое ячеек. Лента может перемещаться вдоль головки так, что в каждый момент времени головка обозревает одну ячейку.
3. Управляющего устройства (УУ), которое в каждый момент времени находится в некотором состоянии. Число состояний конечно. Обозначим множество состояний как {q1,q2,…,qn}. Среди состояний одно соответствует заключительному, при котором МТ останавливается. УУ связано со считывающей головкой.
Кроме того, УУ вырабатывает три команды на перемещение ленты: П, Л, Н, где
П – переместиться на соседнюю справа ячейку;
Л – переместиться соседнюю слева ячейку;
Н – продолжать обозревать ту же ячейку.
Совокупность символов {q1,q2,…,qn} и {П,Л,Н} образуют внутренний алфавит МТ.
Работа машины происходит в дискретном времени. В начальный момент времени в ограниченный участок ленты записано слово в алфавите S, представляющее исходное условие задачи. В остальных ячейках предполагается записанным пустой символ. Управляющее устройство находится в начальном состоянии q1. На каждом шаге работы МТ обозревает на ленте символ Sk и в зависимости от него и от состояния qi, переходит в состояние qj, заменяет Sk на символ Sl и передвигает ленту (либо нет) на одну ячейку.
Каждая элементарная операция имеет вид
qiSk ® qjSl П(Л,Н).
Множество элементарных операций упорядочено и образует абстрактную программу, которая представляет алгоритм.
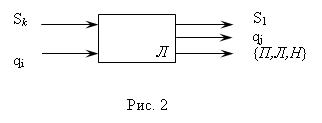
Считывающая головка и управляющее устройство образуют логический блок, который представляет собой (2,3)-полюсник.
SHAPE \* MERGEFORMAT
| Sk |
| S1 |
ЛБ |
| qi |
| qj |
| {П,Л,Н} |
| Рис. 2 |
Структура МТ имеет следующий вид:
| S1 | S2 | … | Sk | … | Sm |
| |
ЛБ |
Q |
P |
| Sl |
| Sk |
| qi |
| qj |
| П(Л,Н) |
Q - ячейка хранит символ состояния, а Р - ячейка – символ сдвига. В них происходит задержка данных символов до начала следующего такта.
В качестве начальной информации на ленту можно записать любую конечную последовательность символов (входное слово) U внешнего алфавита. В начале работы алгоритма устройство управления находится в начальном состоянии, головка обозревает первый слева непустой символ входного слова U. Если после конечного числа тактов МТ останавливается, переходя в заключительное состояние, а на ленте оказывается информация B, то говорят, что машина применима к последовательности U и перерабатывает ее в последовательность B.
Если остановка и сигнал об остановке никогда не поступают, то говорят, что МТ не применима к последовательности U.
Рассмотрим функционирование МТ на примере сложения двух чисел, которые будем изображать в виде набора единиц.
Внешний алфавит будет состоять из символов: {1, +, Ù}, где Ù – пустой символ.
Внутренний алфавит будет состоять из четырех символов {q1, q2, q3, !}, где символ q1 означает начальное состояние, а ! – заключительное состояние.
Пусть на ленте записана начальная информация:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| 1 | 1 | + | 1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||
| 1 | 1 | 1 |
| 1q1 1q3→1q3П +q3→+q3П | Ùq3→1q2H +q2 →+q2Л 1q2→1q2Л Ùq2 →Ùq1П +q1 →Ù!Н |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| 1 | 1 | + | 1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| 1 | + | 1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| 1 | + | 1 | 1 |
После десятого шага YY в состоянии q1 (рис. )
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||
| | + | 1 | 1 |
| q1 | q2 | q3 | |
| 1 | Ùq3П | 1q2Л | 1q3П |
| Ù | Ùq1П | Ùq1П | 1q2H |
| + | Ù!Н | +q2Л | +q3П |
Основная гипотеза теории алгоритмов (тезис Чёрча)
Всякий алгоритм может быть задан посредством тьюринговой функциональной схемы и реализован в соответствующей машине Тьюринга.Обоснование гипотезы.
Речь не идет о доказательстве гипотезы, так как она содержит не формализованные математические понятия.
Уверенность в справедливости гипотезы основана, главным образом, на опыте. Все известные к настоящему времени алгоритмы могут быть заданы посредством тьюринговых функциональных схем. Кроме того, внутри самой теории алгоритмов основная гипотеза не применяется, то есть при доказательстве теорем этой теории ссылок на основную гипотезу не делается.
Машина Тьюринга крайне примитивна. Но примитивность ее не в том, что она использует ленту и механическое движение головки, а то, что ее набор операций с памятью очень прост (запись и чтение символов) и что доступ к памяти в ней происходит не по адресу, а путем последовательного перемещения вдоль ленты. Поэтому выполнение на ней даже таких простых функций как сложение и умножение требует много шагов. Машина Тьюринга была придумана не для того, чтобы производить на ней реальные вычисления, а чтобы показать, что сколь угодно сложный алгоритм можно построить из очень простых операций, причем сами операции и переход от одной операции к другой выполняются автоматически.
Требования к кодированию:
1. различным буквам должны сопоставляться различные кодовые группы, и одна и та же буква везде заменяется одной и той же кодовой группой;
2. Строка текста должна однозначным образом разбиваться на кодовые группы.
Сложность универсальной машины Тьюринга определяется произведением числа символов её внешнего алфавита на число состояний усторйства управления.
Теорема Триттера определяет, что минимальная универсальная машина Тьюринга имеет 4 символа во внешнем алфавите и её УУ имеет 6 состояний.
Под пространственной эффективностью понимают объём памяти, требуемой для выполнения программы.
Временная эффективность программы определяется временем, необходимым для ее выполнения. При этом необходимо учитывать следующие моменты.
Во-первых, время работы программы может ограничиваться ее назначением. Если эта программа реального времени, например, бронирования авиабилетов, то время обработки задания не должно превышать нескольких минут. Если эта программа автоматического управления каким-либо устройством (например, управлением самолёта), то она должна «успевать» отрабатывать поступающую информацию и своевременно выдавать управляющие воздействия.
Во-вторых, бывает важно знать, как изменяется время работы программы при увеличении размерности задачи. Это позволит оценить объем исходных данных, которые могут быть обработаны на компьютере за приемлемое время.
Реальное время работы программы на компьютере зависит не только от выбранного алгоритма. В значительной степени оно определяется типом ЭВМ, структурой представления данных, программной реализацией.
Самым простым способом оценить алгоритм – сопоставить ему число элементарных операций в описании. При реализации это может быть число команд в программе или объём памяти, которую занимает программа. В этом случае оценка d алгоритма A есть некоторое число k: d(A) = k.
Более интересной может быть оценка пары: алгоритма A и конкретной задачи a, которая им решается. Например, оценкой может быть объем памяти под программу, исходные и промежуточные данные, необходимые для решения данной задачи a, или время для решения данной задачи с помощью алгоритма A. В любом случае это будет число d(A(a)) = k(a).
Свойство массовости алгоритма предполагает, что алгоритм будет использоваться для решения класса A подобных задач, с разными исходными данными. Поэтому более сложной оценкой будет оценка как функция свойства задачи. Cопоставим каждой задаче из класса задач, решаемым алгоритмом, некоторый вектор числовых параметров задачи N = (n1, n2, …, nt). В этом случае оценка d(A(A)) = k(N), и это уже будет функция от параметров задачи.
Пример. Необходимо ценить алгоритм Прима – алгоритм выделения минимального остова. В первом случае мы рассматриваем число операторов в описании программы, реализующий алгоритм – число сравнений, условных переходов и т.д. Во втором случае анализируется работа алгоритма (программы) выделения остова некоторого заданного графа и определяется необходимый объём памяти. В последнем случае графу припишем параметры – число вершин в графе и число его рёбер, и сопоставим решению задачи функцию от этих параметров.
Во многих задачах возможно свести вектор задачи к одному параметру. Так, для графа возможно характеризовать его числом вершин, учитывая, что число ребер в нём коррелированно с числом вершин. Для задач, связанных с булевыми функциями, параметром может быть число аргументов функции.
Будем рассматривать только такие задачи. В этом случае оценкой алгоритма будет функция от одного параметра. Временная сложность алгоритма отражает требующиеся для его работы затраты времени Эта функция вставит каждой входной длине n в соответствие максимальное ( по всем индивидуальным задачам длины n) время, затрачиваемое алгоритмом на решение индивидуальных задач этой длины.
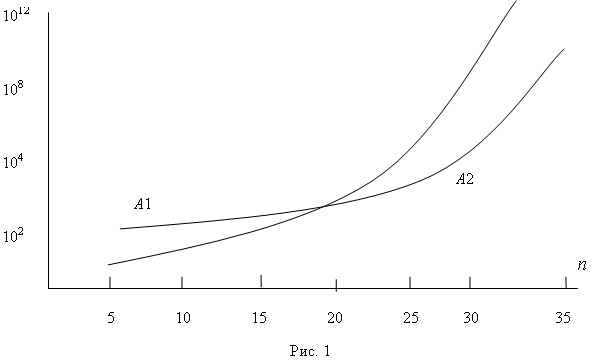
Пример. Пусть функция оценки имеет вид как на рис.1. Необходимо решать задачи с параметром n, лежащим в пределах от 5 до 15. В этом случае необходимо выбрать для реализации алгоритм A1. Если параметр меняется от 20 до 30, лучше использовать алгоритм A2. Если параметр меняется в пределах от 10 до 35, то возможно или выбрать любой из данных алгоритмов, или построить новый алгоритм, который, например, проверяет каждый раз значение параметра и выбирает соответствующий алгоритм.
SHAPE \* MERGEFORMAT
Предположим, что можно рассмотреть все возможные алгоритмы Ai решения задачи a и для каждого параметра n оценить задачу двумя оценками d1(a) = min (d(Ai (a))) и d2(a) = max (d(Ai (a))), где min и max берётся по всем алгоритмам . В этом случае получим две границы решения данной задачи – нижнюю и верхнюю (рис.2). Этот рисунок определяет тот разброс сложности решений задачи и помогает ответить на вопрос: нужно ли тратить силы на поиск хорошего алгоритма или достаточно взять первый попавшийся.
Очень часто возможно оценить исходя из анализа самой задачи вид функции оценки с точностью до некоторого сомножителя – константы. В этом случае эта оценка будет не только оценка алгоритма, но и оценка задачи.
Функция f (n)есть O(g(n)), если существует константа с, такая, что f (n)< O(g(n)) для всех значений n>0.
SHAPE \* MERGEFORMAT

По виду этой функции алгоритмы разделяются на следующие группы:
с линейной оценкой сложности, если функция d=C·n;
с квадратичной сложностью, если d = C · n2;
с полиномиальной сложностью, если d = C0 + C1·n +…+ Ck · nk;
с факториальной сложностью, если d=C·n!;
с экспоненциальной сложностью, если d = C · a n;
с гиперэкспоненциальной сложностью, если d = C · a t, где t = a n.
Здесь C, a и k = некоторые константы, при этом число C может быть очень большим.
В табл. 1 приведена зависимость времени работы алгоритмов различной сложности для задач различной размерности, при условии, что время выполнения одной операции во всех алгоритмах одинаковы. Из таблицы видно, что для полинома, степени 5 задачу размерности 6о решить можно за приемлемое время, в то же время для экспоненциальных алгоритмов уже для размерности, больше 30 задача не решается.
Рост скорости вычислений не уменьшит значение эффективных алгоритмов, что иллюстрирует табл. 2..
Если доказано, что задача является NP – полной, то это означает, что её решение для параметров, имеющих практическое значение, связано с огромными затратами времени или памяти, которые не позволят получить решение. В этом случае необходимо переформулировать задачу. Например, задача поиска минимальной формулы для булевой функции является задачей NP – полной, поэтому при проектировании схем, где эта задача встречается, решают задачу, которую формулируют как поиск функций, близкой к минимальной, для чего пользуются эвристическими алгоритмами, основанными на предположениях здравого смысла. Так, если решается задача размещения объектов в некотором блоке, то разумно начинать размещение с самого большого объекта. В этих алгоритмах не всегда гарантируется получение минимального решения, но если для большинства задач оценка отличается не больше, чем на 10-15% от минимального, то это часто устраивает пользователей.
Пpимеp. Оценим сложность алгоритма Прима поиска минимального остова в графе. Пусть граф описан матрицей смежности.
Алгоритм. Выберем любую вершину и включим её в остов. Рассмотрим связанные с ней ребра. Найдём вершину, связанную с включённой в остов ребром минимального веса и включим её в остов. Для вершин, включённых в остов, рассмотрим связанные с ними рёбра к вершинам, не включённым в остов. Выберем вершину, связанную ребром минимального веса и включим её в остов. Эту процедуру продолжим до тех пор, пока все вершины не будут включены в остов.
Для матричного представления алгоритм примет, следующий вид. Выберем любую вершину и в соответствующей ей строке матрицы найдём ячейку с минимальным весом. Эта процедура потребует n сравнений, где n- порядок матрицы (число вершин в графе). Имя столбца этой ячейки определяет вершину, которую нужно включить в остов. Объединим эти вершины в одну, соответствующую вершинам, включённым в остов. Для этого рассмотрим строки и столбцы этих вершин. Если в i-й ячейке одной из строк не нулевое число, оно запишется в результирующую строку, если ненулевое значение в обеих строках, в результирующую запишем минимальное. Таким образом, для «обработки» одной вершины потребуется число операций, кратных 2 n. Число вершин в рассматриваемом графе сократится на единицу. Повторим то же самое для результирующей строки, пока число вершин не станет равной единицы. Значит, общее число операций оценивается числом, пропорциональным n2, т.е. оценка имеет квадратичную сложность d = C · n2.
Существует большое количество задач, являющихся алгоритмически неразрешимыми. То есть речь идет об отсутствии единого алгоритма, решающего данную задачу. При этом вовсе не исключается возможность решения задачи в частных случаях, но различными способами для каждого случая.
Рассмотрим несколько примеров алгоритмически неразрешимых задач.
1 Задача эквивалентности алгоритмов
По двум произвольно заданным алгоритмам определить будут ли они выдавать одинаковые выходные результаты на любых исходных данных.
2 Задача останова машины Тьюринга
Не существует алгоритма, позволяющего по описанию произвольного алгоритма и его исходных данных определить, останавливается ли алгоритм на этих данных или работает бесконечно.
3 Задача эквивалентности двух слов в ассоциативном исчислении
Ассоциативным исчислением называют совокупность всех слов в некотором алфавите вместе с какой-либо конечной системой допустимых подстановок.
Подстановка P ® Q называется ориентированной. Она заключается в замене фрагмента P в слове R фрагментом Q.
Подстановка P — Q называется неориентированной. Она заключается как в замене фрагмента P в слове R фрагментом Q, так и в замене в слове R фрагмента Q фрагментом P.
Пример. R = ‘aabcb’ P = ‘ab’ Q = ‘bcb’
При P ® Q получим: R' = ‘abcbcb’.
При P — Q получим как R' = ‘abcbcb’, так и R'' = ‘aaab’.
Два слова R1 и R2 называются эквивалентными для заданной системы ориентированных подстановок, если от слова R1 можно, применяя конечное число раз подстановки, перейти к слову R2.
Если же подстановки неориентированы, то возможность перехода требуется как от R1 к R2, так и от R2 к R1.
Задача эквивалентности слов в ассоциативном исчислении состоит в следующем: для любых двух слов в данном исчислении требуется узнать, эквивалентны они или нет.
Задача слов не является надуманной, так как к ней может быть сведена любая известная задача.
Например, рассмотрим задачу поиска пути в лабиринте. Изобразим лабиринт в виде графа, в котором вершинам соответствуют площадки, а ребрам — соединяющие их коридоры. Каждой площадке или вершине графа сопоставим некоторое слово. Каждому коридору или ребру xixj сопоставим неориентированную подстановку, переводящую слово, соответствующее xi, в слово, соответствующее xj.
Например, если вершине x1 соответствует слово ‘xypt’, а смежной вершине x2 — слово ‘xyqt’, то неориентированная подстановка будет иметь вид:
‘p’ — ‘q’.
Задача слов решена для некоторых частных случаев. Например, пусть даны алфавит {x, y, z, p, q} и система неориентированных подстановок:
xz — zx, xp — px, yz — zy, yp — py, xyxz — xyxzq, qzx — xq, qpy — yq.
Спрашивается, эквивалентны ли в данном ассоциативном исчислении слова: xyxxzp и xzypxp?
Ответ: нет, не эквивалентны, так как в первом слове нечетное число букв x, а во втором — четное; система же подстановок сохраняет четность или нечетность букв x в словах.
В общем же случае задача слов алгоритмически неразрешима.
4 Задача распознавания выводимости
С задачей эквивалентности двух слов в ассоциативном исчислении тесно связана задача распознавания выводимости, которая является одной из важнейших задач математической логики.
Задача распознавания выводимости состоит в следующем:
для любых двух слов (формул) S и T в логическом исчислении определить выводима ли формула T из формулы S.
Эта задача также алгоритмически неразрешима.
Теория алгоритмов Методическое пособие по дисциплине «Математическая логика и теория алгоритмов» / В.П. Битюцкий, Н.В. Папуловская. Екатеринбург: ГОУ ВПО УГТУ-УПИ, 2006, с.
Универсальная машина Тьюринга
Универсальная машина позволяет решить любую задачу, если наряду с исходными данными в неё записать алгоритм. Как и любая машина Тьюринга, универсальная машина должна иметь конечные внешний и внутренний алфавиты, в то же время она должна иметь возможность принимать в качестве внешнего алфавита любые алфавиты. Это достигается за счёт кодирования внешнего алфавита в алфавите универсальной машины Тьюринга.Требования к кодированию:
1. различным буквам должны сопоставляться различные кодовые группы, и одна и та же буква везде заменяется одной и той же кодовой группой;
2. Строка текста должна однозначным образом разбиваться на кодовые группы.
Сложность универсальной машины Тьюринга определяется произведением числа символов её внешнего алфавита на число состояний усторйства управления.
Теорема Триттера определяет, что минимальная универсальная машина Тьюринга имеет 4 символа во внешнем алфавите и её УУ имеет 6 состояний.
МЕPЫ СЛОЖНОСТИ АЛГОPИТМОВ
Оценка алгоритма
Оценка алгоритма бывает нужной в том случае, когда при решении некоторой задачи есть несколько разных алгоритмов, и стоит задача выбора одного из них для реализации. Даже если задача решается единственным алгоритмом, бывает нужно оценить сложность его реализации и его работы (объём памяти, время решения).Под пространственной эффективностью понимают объём памяти, требуемой для выполнения программы.
Временная эффективность программы определяется временем, необходимым для ее выполнения. При этом необходимо учитывать следующие моменты.
Во-первых, время работы программы может ограничиваться ее назначением. Если эта программа реального времени, например, бронирования авиабилетов, то время обработки задания не должно превышать нескольких минут. Если эта программа автоматического управления каким-либо устройством (например, управлением самолёта), то она должна «успевать» отрабатывать поступающую информацию и своевременно выдавать управляющие воздействия.
Во-вторых, бывает важно знать, как изменяется время работы программы при увеличении размерности задачи. Это позволит оценить объем исходных данных, которые могут быть обработаны на компьютере за приемлемое время.
Реальное время работы программы на компьютере зависит не только от выбранного алгоритма. В значительной степени оно определяется типом ЭВМ, структурой представления данных, программной реализацией.
Самым простым способом оценить алгоритм – сопоставить ему число элементарных операций в описании. При реализации это может быть число команд в программе или объём памяти, которую занимает программа. В этом случае оценка d алгоритма A есть некоторое число k: d(A) = k.
Более интересной может быть оценка пары: алгоритма A и конкретной задачи a, которая им решается. Например, оценкой может быть объем памяти под программу, исходные и промежуточные данные, необходимые для решения данной задачи a, или время для решения данной задачи с помощью алгоритма A. В любом случае это будет число d(A(a)) = k(a).
Свойство массовости алгоритма предполагает, что алгоритм будет использоваться для решения класса A подобных задач, с разными исходными данными. Поэтому более сложной оценкой будет оценка как функция свойства задачи. Cопоставим каждой задаче из класса задач, решаемым алгоритмом, некоторый вектор числовых параметров задачи N = (n1, n2, …, nt). В этом случае оценка d(A(A)) = k(N), и это уже будет функция от параметров задачи.
Пример. Необходимо ценить алгоритм Прима – алгоритм выделения минимального остова. В первом случае мы рассматриваем число операторов в описании программы, реализующий алгоритм – число сравнений, условных переходов и т.д. Во втором случае анализируется работа алгоритма (программы) выделения остова некоторого заданного графа и определяется необходимый объём памяти. В последнем случае графу припишем параметры – число вершин в графе и число его рёбер, и сопоставим решению задачи функцию от этих параметров.
Во многих задачах возможно свести вектор задачи к одному параметру. Так, для графа возможно характеризовать его числом вершин, учитывая, что число ребер в нём коррелированно с числом вершин. Для задач, связанных с булевыми функциями, параметром может быть число аргументов функции.
Будем рассматривать только такие задачи. В этом случае оценкой алгоритма будет функция от одного параметра. Временная сложность алгоритма отражает требующиеся для его работы затраты времени Эта функция вставит каждой входной длине n в соответствие максимальное ( по всем индивидуальным задачам длины n) время, затрачиваемое алгоритмом на решение индивидуальных задач этой длины.
Пример. Пусть функция оценки имеет вид как на рис.1. Необходимо решать задачи с параметром n, лежащим в пределах от 5 до 15. В этом случае необходимо выбрать для реализации алгоритм A1. Если параметр меняется от 20 до 30, лучше использовать алгоритм A2. Если параметр меняется в пределах от 10 до 35, то возможно или выбрать любой из данных алгоритмов, или построить новый алгоритм, который, например, проверяет каждый раз значение параметра и выбирает соответствующий алгоритм.
SHAPE \* MERGEFORMAT
| A1 |
| A2 |
| 5 10 15 20 25 30 35 |
| 1012 108 104 102 102 102 102 |
| Рис. 1 |
| n |
Предположим, что можно рассмотреть все возможные алгоритмы Ai решения задачи a и для каждого параметра n оценить задачу двумя оценками d1(a) = min (d(Ai (a))) и d2(a) = max (d(Ai (a))), где min и max берётся по всем алгоритмам . В этом случае получим две границы решения данной задачи – нижнюю и верхнюю (рис.2). Этот рисунок определяет тот разброс сложности решений задачи и помогает ответить на вопрос: нужно ли тратить силы на поиск хорошего алгоритма или достаточно взять первый попавшийся.
Очень часто возможно оценить исходя из анализа самой задачи вид функции оценки с точностью до некоторого сомножителя – константы. В этом случае эта оценка будет не только оценка алгоритма, но и оценка задачи.
Функция f (n)есть O(g(n)), если существует константа с, такая, что f (n)< O(g(n)) для всех значений n>0.
SHAPE \* MERGEFORMAT
| |
| Рис. 2 |
| n |
| d2(a) |
| 5 10 15 20 25 30 35 |
| 1012 108 104 102 102 102 102 |
| d1(a) |
По виду этой функции алгоритмы разделяются на следующие группы:
с линейной оценкой сложности, если функция d=C·n;
с квадратичной сложностью, если d = C · n2;
с полиномиальной сложностью, если d = C0 + C1·n +…+ Ck · nk;
с факториальной сложностью, если d=C·n!;
с экспоненциальной сложностью, если d = C · a n;
с гиперэкспоненциальной сложностью, если d = C · a t, где t = a n.
Здесь C, a и k = некоторые константы, при этом число C может быть очень большим.
Практические и NP-полные алгоритмы
По виду функций алгоритмы (и соответствующие задачи) делятся на два класса. К первому относятся алгоритмы групп 1-3, когда для полиномиальных алгоритмов k≤ 7. Эти алгоритмы называются практическими. Все другие алгоритмы составляют второй класс и называются NP – полными.В табл. 1 приведена зависимость времени работы алгоритмов различной сложности для задач различной размерности, при условии, что время выполнения одной операции во всех алгоритмах одинаковы. Из таблицы видно, что для полинома, степени 5 задачу размерности 6о решить можно за приемлемое время, в то же время для экспоненциальных алгоритмов уже для размерности, больше 30 задача не решается.
| Таблица 1. | ||||||
| Сложность задачи | ||||||
| Сложность алгоритма | 10 | 20 | 30 | 40 | 50 | 60 |
| N | 0.00001с | 0,00002с | 0,00003с | 0,0004с | 0,0005с | 0,00006с |
| N^2 | 0,0001с | 0,0004с | 0,0009с | 0,0016с | 0,025с | 0,0036с |
| N^3 | 0,001с | 0,008с | 0,027с | 0,064с | 0,125с | 0,216с |
| N^5 | 0,1 c | 3,2 c | 24,3 c | 1,7 мин | 5,2 мин | 13,0мин |
| 2^n | 0,001 c | 1 c | 17,9 мин | 12,7 дней | 35,7 лет | 366 столетий |
| 3^n | 0,059c | 58 мин | 6,5 лет | 3855 столетий | 2*10^8стол | 1,3*10^13 стол |
| Таблица 2 | |||
| Сложность алгоритма | Максимальный размер задачи, разрешимый за единицу времени | ||
| На современных ЭВМ | Если производ*10 | Если производ*1000 | |
| N | k | 10k | 1000k |
| Nlog n | k | Почти 10k при больших к | Почти 10k при больших к |
| N^2 | k | 3,16k | 31,6k |
| N^3 | k | 2,15k | 10k |
| 2^n | k | K+3,3 | K+9,97 |
Пpимеp. Оценим сложность алгоритма Прима поиска минимального остова в графе. Пусть граф описан матрицей смежности.
Алгоритм. Выберем любую вершину и включим её в остов. Рассмотрим связанные с ней ребра. Найдём вершину, связанную с включённой в остов ребром минимального веса и включим её в остов. Для вершин, включённых в остов, рассмотрим связанные с ними рёбра к вершинам, не включённым в остов. Выберем вершину, связанную ребром минимального веса и включим её в остов. Эту процедуру продолжим до тех пор, пока все вершины не будут включены в остов.
Для матричного представления алгоритм примет, следующий вид. Выберем любую вершину и в соответствующей ей строке матрицы найдём ячейку с минимальным весом. Эта процедура потребует n сравнений, где n- порядок матрицы (число вершин в графе). Имя столбца этой ячейки определяет вершину, которую нужно включить в остов. Объединим эти вершины в одну, соответствующую вершинам, включённым в остов. Для этого рассмотрим строки и столбцы этих вершин. Если в i-й ячейке одной из строк не нулевое число, оно запишется в результирующую строку, если ненулевое значение в обеих строках, в результирующую запишем минимальное. Таким образом, для «обработки» одной вершины потребуется число операций, кратных 2 n. Число вершин в рассматриваемом графе сократится на единицу. Повторим то же самое для результирующей строки, пока число вершин не станет равной единицы. Значит, общее число операций оценивается числом, пропорциональным n2, т.е. оценка имеет квадратичную сложность d = C · n2.
Алгоритмически неразрешимые проблемы
Задачи, для которых доказано, что решающего их алгоритма не существует, называются алгоритмически неразрешимыми.Существует большое количество задач, являющихся алгоритмически неразрешимыми. То есть речь идет об отсутствии единого алгоритма, решающего данную задачу. При этом вовсе не исключается возможность решения задачи в частных случаях, но различными способами для каждого случая.
Рассмотрим несколько примеров алгоритмически неразрешимых задач.
1 Задача эквивалентности алгоритмов
По двум произвольно заданным алгоритмам определить будут ли они выдавать одинаковые выходные результаты на любых исходных данных.
2 Задача останова машины Тьюринга
Не существует алгоритма, позволяющего по описанию произвольного алгоритма и его исходных данных определить, останавливается ли алгоритм на этих данных или работает бесконечно.
3 Задача эквивалентности двух слов в ассоциативном исчислении
Ассоциативным исчислением называют совокупность всех слов в некотором алфавите вместе с какой-либо конечной системой допустимых подстановок.
Подстановка P ® Q называется ориентированной. Она заключается в замене фрагмента P в слове R фрагментом Q.
Подстановка P — Q называется неориентированной. Она заключается как в замене фрагмента P в слове R фрагментом Q, так и в замене в слове R фрагмента Q фрагментом P.
Пример. R = ‘aabcb’ P = ‘ab’ Q = ‘bcb’
При P ® Q получим: R' = ‘abcbcb’.
При P — Q получим как R' = ‘abcbcb’, так и R'' = ‘aaab’.
Два слова R1 и R2 называются эквивалентными для заданной системы ориентированных подстановок, если от слова R1 можно, применяя конечное число раз подстановки, перейти к слову R2.
Если же подстановки неориентированы, то возможность перехода требуется как от R1 к R2, так и от R2 к R1.
Задача эквивалентности слов в ассоциативном исчислении состоит в следующем: для любых двух слов в данном исчислении требуется узнать, эквивалентны они или нет.
Задача слов не является надуманной, так как к ней может быть сведена любая известная задача.
Например, рассмотрим задачу поиска пути в лабиринте. Изобразим лабиринт в виде графа, в котором вершинам соответствуют площадки, а ребрам — соединяющие их коридоры. Каждой площадке или вершине графа сопоставим некоторое слово. Каждому коридору или ребру xixj сопоставим неориентированную подстановку, переводящую слово, соответствующее xi, в слово, соответствующее xj.
Например, если вершине x1 соответствует слово ‘xypt’, а смежной вершине x2 — слово ‘xyqt’, то неориентированная подстановка будет иметь вид:
‘p’ — ‘q’.
Задача слов решена для некоторых частных случаев. Например, пусть даны алфавит {x, y, z, p, q} и система неориентированных подстановок:
xz — zx, xp — px, yz — zy, yp — py, xyxz — xyxzq, qzx — xq, qpy — yq.
Спрашивается, эквивалентны ли в данном ассоциативном исчислении слова: xyxxzp и xzypxp?
Ответ: нет, не эквивалентны, так как в первом слове нечетное число букв x, а во втором — четное; система же подстановок сохраняет четность или нечетность букв x в словах.
В общем же случае задача слов алгоритмически неразрешима.
4 Задача распознавания выводимости
С задачей эквивалентности двух слов в ассоциативном исчислении тесно связана задача распознавания выводимости, которая является одной из важнейших задач математической логики.
Задача распознавания выводимости состоит в следующем:
для любых двух слов (формул) S и T в логическом исчислении определить выводима ли формула T из формулы S.
Эта задача также алгоритмически неразрешима.
Теория алгоритмов Методическое пособие по дисциплине «Математическая логика и теория алгоритмов» / В.П. Битюцкий, Н.В. Папуловская. Екатеринбург: ГОУ ВПО УГТУ-УПИ, 2006, с.