Реферат на тему Программирование различных типов задач
Работа добавлена на сайт bukvasha.net: 2014-08-05Поможем написать учебную работу
Если у вас возникли сложности с курсовой, контрольной, дипломной, рефератом, отчетом по практике, научно-исследовательской и любой другой работой - мы готовы помочь.

Предоплата всего
от 25%

Подписываем
договор
МУНИЦИПАЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ГИМНАЗИЯ №64
Программирование различных типов задач
Экзаменационный реферат по информатике
Медведев Александр Валерьевич, 11Б
Кушникова Валерия Петровна, учитель
Липецк 2007
Содержание
I. Введение
II. Основная часть:
1.Способы сортировки
2. Теория чисел
3. Задача «Красивые числа»
III. Список используемой литературы
Вступление
При программировании очень важно понять, насколько мощным является то, что вы знаете. В принципе любой интересный алгоритм/программу можно написать, основываясь на тех знаниях, которые вы получили в самом начале обучения программирования. Все мощные способности современных языков не обязательны для построения интересных вещей – они нужны только для того, чтобы построить их более четко и удобно. Говоря другими словами, хорошим писателем становится не тот, кто выучил много слов из словаря, а тот, кто нашел, о чем рассказать.
Для написания качественных программ, можно дать несколько простых советов:
- Пишите сначала комментарии. Начинайте ваши программы и процедуры с нескольких предложений, которые объясняют то, что они должны делать. Это важно, потому что если вы не сможете с легкостью написать эти комментарии, то, вероятнее всего, вы не понимаете, что делает программа. Редактировать комментарии гораздо проще, чем редактировать программу , поэтому время, потраченное на дополнительное печатание, потрачено с большой выгодой. Конечно из-за того, что на соревнованиях обычно поджимает время, появляется привычка быть небрежным, но в этом нет ничего хорошего.
- Документируйте каждую переменную. Напишите одну строку комментария для каждой переменной, чтобы бы вы знали, что она делает. И снова, если вы не можете четко это написать, то вы не понимаете, что она тут делает. Вы будете общаться с программой, по крайней мере, несколько циклов отладки, и вы оцените это скромное вложение в ее читабельность.
- Используйте символьные константы. Когда бы вам ни потребовалась константа в вашей программе(размер входных данных, математическая константа, размер структуры данных и т.д.), объявляйте ее в самом начале программы. Использование противоречивых констант может привести к очень сложным и труднообнаруживаемым ошибкам. Конечно, символьное имя нужно только тогда, когда вы собираетесь его использовать в том месте, где должна быть константа
- Используйте подпрограммы, чтобы избежать излишнего кода. Гораздо безопаснее написать одну подпрограмму и вызывать ее с соответствующими параметрами, чем повторять одно и тоже с разными переменными.
Сортировка
Сортировка является наиболее фундаментальной алгоритмической задачей в теории вычислительных машин и систем по двум различным причинам. Во-первых, сортировка – это полезная операция, которая эффективно решает многие задачи, с которыми встречается каждый программист. Во-вторых, были разработаны буквально десятки различных алгоритмов сортировки, каждый из которых основывается на определенной хитрой идее или наблюдении. Большинство примеров разработки алгоритмов ведет к интересным алгоритмам, включающим «разделяй и властвуй», рандомизацию, инкрементную вставку и продвинутые структуры данных. Из свойств этих алгоритмов следует множество интересных задач по программированию.
Ключом к пониманию сортировки является понимание того, как она может быть использована для решения многих важных задач программирования. Рассмотрим некоторые случаи применения сортировки.
· Проверка уникальности. Как мы можем проверить, все ли элементы данного набора объектов S являются различными? Отсортируем их либо в возрастающем, либо в убывающем порядке, так что любые повторяющиеся объекты будут следовать друг за другом. После этого один проход по всем элементам с проверкой равенства S[i]=s[i+1] для любого 1≤i<n решает поставленную задачу.
· Удаление повторяющихся элементов. Как мы можем удалить все копии, кроме одной, любого из повторяющихся элементов S? Сортировка и чистка снова решают задачу. Обратите внимание, что чистку проще всего производить, использую два индекса – back, указывающий на последний элемент в очищенной части массива, и i, указывающий на следующий элемент, который нужно рассмотреть. Если S[back]<>S[i], увеличиваем back и копируем S[i] в S[back].
· Распределение приоритетов событий. Предположим, что у нас имеется список работ, которые необходимо сделать, и для каждой определен свой собственный срок сдачи. Сортировка объектов по времени сдачи (или по аналогичному критерию) расположит работы в том порядке, в котором их необходимо делать. Очереди по приоритетам удобны для работы с календарями и расписаниями, когда имеется операции вставки и удаления, но сортировка удобна в том случае, когда набор событий не меняется в ходе выполнения.
· Медиана/выбор. Предположим, что мы хотим найти k-й по величине объект в S. После сортировки объектов в порядке возрастания нужный нам будет находится в ячейке S[k]. В определенных случаях этот подход может быть использован для нахождения наименьшего, наибольшего и медианного объекта.
· Расчет частоты. Какой элемент чаще всего встречается в S? После сортировки линейный проход позволяет нам посчитать число раз, которое встречается каждый элемент.
· Восстановление первоначального порядка. Как мы можем восстановить первоначальное расположение набора объектов, после того как мы переставили их для некоторых целей? Добавим дополнительное поле к записи данных объекта, такое что i-й записи это поле равняется i. Сохранив это поле во время всех перестановок, мы сможем отсортировать по нему тогда, когда нам потребуется восстановить первоначальный порядок.
· Создание пересечения/объединения. Как мы можем рассчитать пересечение или объединение двух контейнеров? Если они оба отсортированы, мы может объединить их, если будем выбирать наименьший из двух ведущих элементов, помещать его в новое множество, если хотим, а затем удалять из соответствующего списка.
· Поиск необходимой пары. Как мы можем проверить, существуют ли два целых числа x,y 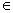
S таких ,что x+y=z для какого-то заданного z? Вместо того, чтобы перебирать все возможные пары, отсортируем числа в порядке возрастания. С ростом S[i], при увеличении I, его возможный партнер j, такой что S[j]=z-S[i], уменьшается. Таким образом, уменьшая j соответствующим образом при увеличении I, мы получаем изящное решение.
· Эффективный поиск. Как мы можем эффективно проверить, принадлежит ли элемент s множеству S? Конечно, упорядочивание множества с целью применения эффективного бинарного поиска – это, наверное, наиболее стандартное приложение сортировки. Просто не забывайте остальные!
Рассмотрим несколько достаточно поучительных алгоритмов сортировки
Сортировка пузырьком
Расположим массив сверху вниз, от нулевого элемента - к последнему. Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.

После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию... Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.

Type
arrType = Array[1 .. n] Of Integer;
Procedure Bubble(Var ar: arrType; n: integer);
Var i, j, T: Integer;
Begin
For i := 1 To n Do
For j := n DownTo i+1 Do
If ar[Pred(j)] > ar[j] Then Begin { < }
T := ar[Pred(j)]; ar[Pred(j)] := ar[j]; ar[j] := T
End
End;
Сложность этого метода сортировки составляет О(n^2)
Пузырьковая сортировка с просеиванием
Аналогичен методу пузырьковой сортировки, но после перестановки пары соседних элементов выполняется просеивание: наименьший левый элемент продвигается к началу массива насколько это возможно, пока не выполняется условие упорядоченности.
Преимущество: простой метод пузырька работает крайне медленно, когда мин/макс (в зависимости от направления сортировки) элемент массива стоит в конце, этот алгоритм - намного быстрее.
const n = 10;
var
x: array[1 .. n] of integer;
i, j, t: integer;
flagsort: boolean;
procedure bubble_P;
begin
repeat
flagsort:=true;
for i:=1 to n-1 do
if not(x[i]<=x[i+1]) then begin
t:=x[i];
x[i]:=x[i+1];
x[i+1]:=t;
j:=i;
while (j>1)and not(x[j-1]<=x[j]) do begin
t:=x[j];
x[j]:=x[j-1];
x[j-1]:=t;
dec(j);
end;
flagsort:=false;
end;
until flagsort;
end;
Тестировалось на массиве целых чисел (25000 элементов).
Прирост скорости относительно простой пузырьковой сортировки - около 75%...
Метод последовательного поиска минимумов
Теория: Просматривается весь массив, ищется минимальный элемент и ставится на место первого, "старый" первый элемент ставится на место найденного
type
TArr = array[1..100] of integer;
var
mass1 : TArr;
n : integer;
procedure NextMinSearchSort(var mass:TArr; size:integer);
var i, j, Nmin, temp: integer;
begin
for i:=1 to size-1 do begin
nmin:=i;
for j:=i+1 to size do
if mass[j]<mass[Nmin] then Nmin:=j;
temp:=mass[i];
mass[i]:=mass[Nmin];
mass[Nmin]:=temp;
end;
end;
Сортировка вставками
Сортировка простыми вставками в чем-то похожа на вышеизложенные методы. Аналогичным образом делаются проходы по части массива, и аналогичным же образом в его начале "вырастает" отсортированная последовательность... Однако в сортировке пузырьком или выбором можно было четко заявить, что на i-м шаге элементы a[0]...a[i] стоят на правильных местах и никуда более не переместятся. Здесь же подобное утверждение будет более слабым: последовательность a[0]...a[i] упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы. Будем разбирать алгоритм, рассматривая его действия на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]...a[i] и неупорядоченную a[i+1]...a[n]. На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива. Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним. В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется.

Таким образом, в процессе вставки мы "просеиваем" элемент x к началу массива, останавливаясь в случае, когда
1. Hайден элемент, меньший x или
2. Достигнуто начало последовательности.
Type
arrType = Array[1 .. n] Of Integer;
Procedure Insert(Var ar: arrType; n: Integer);
Var i, j, T: Integer;
Begin
For i := 1 To n Do Begin
T := ar[i];
j := Pred(i);
While (T < ar[j]) and (j > 0) Do Begin
ar[Succ(j)] := ar[j]; Dec(j);
End;
ar[Succ(j)] := T;
End;
End;
Сложность О(n^2)
Распределяющая сортировка - RadixSort - цифровая – поразрядная
Пусть имеем максимум по k байт в каждом ключе (хотя за элемент сортировки вполне можно принять и что-либо другое, например слово - двойной байт, или буквы, если сортируются строки). k должно быть известно заранее, до сортировки.
Разрядность данных (количество возможных значений элементов) - m - также должна быть известна заранее и постоянна. Если мы сортируем слова, то элемент сортировки - буква, m = 33. Если в самом длинном слове 10 букв, k = 10. Обычно мы будем сортировать данные по ключам из k байт, m=256.
Пусть у нас есть массив source из n элементов по одному байту в каждом.
Для примера можете выписать на листочек массив source = <7, 9, 8, 5, 4, 7, 7>, и проделать с ним все операции, имея в виду m=9.
I. Составим таблицу распределения. В ней будет m (256) значений и заполняться она будет так:
for i := 0 to Pred(255) Do distr[i]:=0;
for i := 0 to Pred(n) Do distr[source[i]] := distr[[i]] + 1;
Для нашего примера будем иметь distr = <0, 0, 0, 0, 1, 1, 0, 3, 1, 1>, то есть i-ый элемент distr[] - количество ключей со значением i.
II. Заполним таблицу индексов:
index: array[0 .. 255] of integer;
index[0]:=0;
for i := 1 to Pred(255) Do index[i]=index[i-1]+distr[i-1];
В index[ i ] мы поместили информацию о будущем количестве символов в отсортированном массиве до символа с ключом i.
Hапример, index[8] = 5 : имеем <4, 5, 7, 7, 7, 8>.
III. А теперь заполняем новосозданный массив sorted размера n:
for i := 0 to Pred(n) Do Begin
sorted[ index[ source[i] ] ]:=source[i];
{
попутно изменяем index уже вставленных символов, чтобы
одинаковые ключи шли один за другим:
}
index[ source[i] ] := index[ source[i] ] +1;
End;
Итак, мы научились за O(n) сортировать байты. А от байтов до строк и чисел - 1 шаг. Пусть у нас в каждом числе - k байт.
Будем действовать в десятичной системе и сортировать обычные числа ( m = 10 ).
сначала они в сортируем по младшему на один беспорядке: разряду: выше: и еще раз:
523 523 523 088
153 153 235 153
088 554 153 235
554 235 554 523
235 088 088 554
Hу вот мы и отсортировали за O(k*n) шагов. Если количество возможных различных ключей ненамного превышает общее их число, то 'поразрядная сортировка' оказывается гораздо быстрее даже 'быстрой сортировки'!
Реализация алгоритма "распределяющей" сортировки:
Const
n = 8;
Type
arrType = Array[0 .. Pred(n)] Of Byte;
Const
m = 256;
a: arrType =
(44, 55, 12, 42, 94, 18, 6, 67);
Procedure RadixSort(Var source, sorted: arrType);
Type
indexType = Array[0 .. Pred(m)] Of Byte;
Var
distr, index: indexType;
i: integer;
begin
fillchar(distr, sizeof(distr), 0);
for i := 0 to Pred(n) do
inc(distr[source[i]]);
index[0] := 0;
for i := 1 to Pred(m) do
index[i] := index[Pred(i)] + distr[Pred(i)];
for i := 0 to Pred(n) do
begin
sorted[ index[source[i]] ] := source[i];
index[source[i]] := index[source[i]]+1;
end;
end;
var
b: arrType;
begin
RadixSort(a, b);
end.
Теория чисел.
Теория чисел является, возможно, самым интересным и красивым разделом математики. Доказательство Евклидом существования бесконечного количества простых чисел остается таким же четким и ясным сегодня, каким оно было более двух тысяч лет назад. Такие невинные вопросы, как существуют ли решения уравнения аn+bn=cn для целых a,b,c и n>2, часто оказывается совсем не такими невинными. Более того, это формулировка великой теоремы Ферма!
ГИМНАЗИЯ №64
Программирование различных типов задач
Экзаменационный реферат по информатике
Медведев Александр Валерьевич, 11Б
Кушникова Валерия Петровна, учитель
Липецк 2007
Содержание
I. Введение
II. Основная часть:
1.Способы сортировки
2. Теория чисел
3. Задача «Красивые числа»
III. Список используемой литературы
Вступление
При программировании очень важно понять, насколько мощным является то, что вы знаете. В принципе любой интересный алгоритм/программу можно написать, основываясь на тех знаниях, которые вы получили в самом начале обучения программирования. Все мощные способности современных языков не обязательны для построения интересных вещей – они нужны только для того, чтобы построить их более четко и удобно. Говоря другими словами, хорошим писателем становится не тот, кто выучил много слов из словаря, а тот, кто нашел, о чем рассказать.
Для написания качественных программ, можно дать несколько простых советов:
- Пишите сначала комментарии. Начинайте ваши программы и процедуры с нескольких предложений, которые объясняют то, что они должны делать. Это важно, потому что если вы не сможете с легкостью написать эти комментарии, то, вероятнее всего, вы не понимаете, что делает программа. Редактировать комментарии гораздо проще, чем редактировать программу , поэтому время, потраченное на дополнительное печатание, потрачено с большой выгодой. Конечно из-за того, что на соревнованиях обычно поджимает время, появляется привычка быть небрежным, но в этом нет ничего хорошего.
- Документируйте каждую переменную. Напишите одну строку комментария для каждой переменной, чтобы бы вы знали, что она делает. И снова, если вы не можете четко это написать, то вы не понимаете, что она тут делает. Вы будете общаться с программой, по крайней мере, несколько циклов отладки, и вы оцените это скромное вложение в ее читабельность.
- Используйте символьные константы. Когда бы вам ни потребовалась константа в вашей программе(размер входных данных, математическая константа, размер структуры данных и т.д.), объявляйте ее в самом начале программы. Использование противоречивых констант может привести к очень сложным и труднообнаруживаемым ошибкам. Конечно, символьное имя нужно только тогда, когда вы собираетесь его использовать в том месте, где должна быть константа
- Используйте подпрограммы, чтобы избежать излишнего кода. Гораздо безопаснее написать одну подпрограмму и вызывать ее с соответствующими параметрами, чем повторять одно и тоже с разными переменными.
Сортировка
Сортировка является наиболее фундаментальной алгоритмической задачей в теории вычислительных машин и систем по двум различным причинам. Во-первых, сортировка – это полезная операция, которая эффективно решает многие задачи, с которыми встречается каждый программист. Во-вторых, были разработаны буквально десятки различных алгоритмов сортировки, каждый из которых основывается на определенной хитрой идее или наблюдении. Большинство примеров разработки алгоритмов ведет к интересным алгоритмам, включающим «разделяй и властвуй», рандомизацию, инкрементную вставку и продвинутые структуры данных. Из свойств этих алгоритмов следует множество интересных задач по программированию.
Ключом к пониманию сортировки является понимание того, как она может быть использована для решения многих важных задач программирования. Рассмотрим некоторые случаи применения сортировки.
· Проверка уникальности. Как мы можем проверить, все ли элементы данного набора объектов S являются различными? Отсортируем их либо в возрастающем, либо в убывающем порядке, так что любые повторяющиеся объекты будут следовать друг за другом. После этого один проход по всем элементам с проверкой равенства S[i]=s[i+1] для любого 1≤i<n решает поставленную задачу.
· Удаление повторяющихся элементов. Как мы можем удалить все копии, кроме одной, любого из повторяющихся элементов S? Сортировка и чистка снова решают задачу. Обратите внимание, что чистку проще всего производить, использую два индекса – back, указывающий на последний элемент в очищенной части массива, и i, указывающий на следующий элемент, который нужно рассмотреть. Если S[back]<>S[i], увеличиваем back и копируем S[i] в S[back].
· Распределение приоритетов событий. Предположим, что у нас имеется список работ, которые необходимо сделать, и для каждой определен свой собственный срок сдачи. Сортировка объектов по времени сдачи (или по аналогичному критерию) расположит работы в том порядке, в котором их необходимо делать. Очереди по приоритетам удобны для работы с календарями и расписаниями, когда имеется операции вставки и удаления, но сортировка удобна в том случае, когда набор событий не меняется в ходе выполнения.
· Медиана/выбор. Предположим, что мы хотим найти k-й по величине объект в S. После сортировки объектов в порядке возрастания нужный нам будет находится в ячейке S[k]. В определенных случаях этот подход может быть использован для нахождения наименьшего, наибольшего и медианного объекта.
· Расчет частоты. Какой элемент чаще всего встречается в S? После сортировки линейный проход позволяет нам посчитать число раз, которое встречается каждый элемент.
· Восстановление первоначального порядка. Как мы можем восстановить первоначальное расположение набора объектов, после того как мы переставили их для некоторых целей? Добавим дополнительное поле к записи данных объекта, такое что i-й записи это поле равняется i. Сохранив это поле во время всех перестановок, мы сможем отсортировать по нему тогда, когда нам потребуется восстановить первоначальный порядок.
· Создание пересечения/объединения. Как мы можем рассчитать пересечение или объединение двух контейнеров? Если они оба отсортированы, мы может объединить их, если будем выбирать наименьший из двух ведущих элементов, помещать его в новое множество, если хотим, а затем удалять из соответствующего списка.
· Поиск необходимой пары. Как мы можем проверить, существуют ли два целых числа x,y
· Эффективный поиск. Как мы можем эффективно проверить, принадлежит ли элемент s множеству S? Конечно, упорядочивание множества с целью применения эффективного бинарного поиска – это, наверное, наиболее стандартное приложение сортировки. Просто не забывайте остальные!
Рассмотрим несколько достаточно поучительных алгоритмов сортировки
Сортировка пузырьком
Расположим массив сверху вниз, от нулевого элемента - к последнему. Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.
После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию... Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.
arrType = Array[1 .. n] Of Integer;
Procedure Bubble(Var ar: arrType; n: integer);
Var i, j, T: Integer;
Begin
For i := 1 To n Do
For j := n DownTo i+1 Do
If ar[Pred(j)] > ar[j] Then Begin { < }
T := ar[Pred(j)]; ar[Pred(j)] := ar[j]; ar[j] := T
End
End;
Сложность этого метода сортировки составляет О(n^2)
Пузырьковая сортировка с просеиванием
Аналогичен методу пузырьковой сортировки, но после перестановки пары соседних элементов выполняется просеивание: наименьший левый элемент продвигается к началу массива насколько это возможно, пока не выполняется условие упорядоченности.
Преимущество: простой метод пузырька работает крайне медленно, когда мин/макс (в зависимости от направления сортировки) элемент массива стоит в конце, этот алгоритм - намного быстрее.
const n = 10;
var
x: array[1 .. n] of integer;
i, j, t: integer;
flagsort: boolean;
procedure bubble_P;
begin
repeat
flagsort:=true;
for i:=1 to n-1 do
if not(x[i]<=x[i+1]) then begin
t:=x[i];
x[i]:=x[i+1];
x[i+1]:=t;
j:=i;
while (j>1)and not(x[j-1]<=x[j]) do begin
t:=x[j];
x[j]:=x[j-1];
x[j-1]:=t;
dec(j);
end;
flagsort:=false;
end;
until flagsort;
end;
Тестировалось на массиве целых чисел (25000 элементов).
Прирост скорости относительно простой пузырьковой сортировки - около 75%...
Метод последовательного поиска минимумов
Теория: Просматривается весь массив, ищется минимальный элемент и ставится на место первого, "старый" первый элемент ставится на место найденного
type
TArr = array[1..100] of integer;
var
mass1 : TArr;
n : integer;
procedure NextMinSearchSort(var mass:TArr; size:integer);
var i, j, Nmin, temp: integer;
begin
for i:=1 to size-1 do begin
nmin:=i;
for j:=i+1 to size do
if mass[j]<mass[Nmin] then Nmin:=j;
temp:=mass[i];
mass[i]:=mass[Nmin];
mass[Nmin]:=temp;
end;
end;
Сортировка вставками
Сортировка простыми вставками в чем-то похожа на вышеизложенные методы. Аналогичным образом делаются проходы по части массива, и аналогичным же образом в его начале "вырастает" отсортированная последовательность... Однако в сортировке пузырьком или выбором можно было четко заявить, что на i-м шаге элементы a[0]...a[i] стоят на правильных местах и никуда более не переместятся. Здесь же подобное утверждение будет более слабым: последовательность a[0]...a[i] упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы. Будем разбирать алгоритм, рассматривая его действия на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]...a[i] и неупорядоченную a[i+1]...a[n]. На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива. Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним. В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется.
Таким образом, в процессе вставки мы "просеиваем" элемент x к началу массива, останавливаясь в случае, когда
1. Hайден элемент, меньший x или
2. Достигнуто начало последовательности.
Type
arrType = Array[1 .. n] Of Integer;
Procedure Insert(Var ar: arrType; n: Integer);
Var i, j, T: Integer;
Begin
For i := 1 To n Do Begin
T := ar[i];
j := Pred(i);
While (T < ar[j]) and (j > 0) Do Begin
ar[Succ(j)] := ar[j]; Dec(j);
End;
ar[Succ(j)] := T;
End;
End;
Сложность О(n^2)
Распределяющая сортировка - RadixSort - цифровая – поразрядная
Пусть имеем максимум по k байт в каждом ключе (хотя за элемент сортировки вполне можно принять и что-либо другое, например слово - двойной байт, или буквы, если сортируются строки). k должно быть известно заранее, до сортировки.
Разрядность данных (количество возможных значений элементов) - m - также должна быть известна заранее и постоянна. Если мы сортируем слова, то элемент сортировки - буква, m = 33. Если в самом длинном слове 10 букв, k = 10. Обычно мы будем сортировать данные по ключам из k байт, m=256.
Пусть у нас есть массив source из n элементов по одному байту в каждом.
Для примера можете выписать на листочек массив source = <7, 9, 8, 5, 4, 7, 7>, и проделать с ним все операции, имея в виду m=9.
I. Составим таблицу распределения. В ней будет m (256) значений и заполняться она будет так:
for i := 0 to Pred(255) Do distr[i]:=0;
for i := 0 to Pred(n) Do distr[source[i]] := distr[[i]] + 1;
Для нашего примера будем иметь distr = <0, 0, 0, 0, 1, 1, 0, 3, 1, 1>, то есть i-ый элемент distr[] - количество ключей со значением i.
II. Заполним таблицу индексов:
index: array[0 .. 255] of integer;
index[0]:=0;
for i := 1 to Pred(255) Do index[i]=index[i-1]+distr[i-1];
В index[ i ] мы поместили информацию о будущем количестве символов в отсортированном массиве до символа с ключом i.
Hапример, index[8] = 5 : имеем <4, 5, 7, 7, 7, 8>.
III. А теперь заполняем новосозданный массив sorted размера n:
for i := 0 to Pred(n) Do Begin
sorted[ index[ source[i] ] ]:=source[i];
{
попутно изменяем index уже вставленных символов, чтобы
одинаковые ключи шли один за другим:
}
index[ source[i] ] := index[ source[i] ] +1;
End;
Итак, мы научились за O(n) сортировать байты. А от байтов до строк и чисел - 1 шаг. Пусть у нас в каждом числе - k байт.
Будем действовать в десятичной системе и сортировать обычные числа ( m = 10 ).
сначала они в сортируем по младшему на один беспорядке: разряду: выше: и еще раз:
523 523 523 088
153 153 235 153
088 554 153 235
554 235 554 523
235 088 088 554
Hу вот мы и отсортировали за O(k*n) шагов. Если количество возможных различных ключей ненамного превышает общее их число, то 'поразрядная сортировка' оказывается гораздо быстрее даже 'быстрой сортировки'!
Реализация алгоритма "распределяющей" сортировки:
Const
n = 8;
Type
arrType = Array[0 .. Pred(n)] Of Byte;
Const
m = 256;
a: arrType =
(44, 55, 12, 42, 94, 18, 6, 67);
Procedure RadixSort(Var source, sorted: arrType);
Type
indexType = Array[0 .. Pred(m)] Of Byte;
Var
distr, index: indexType;
i: integer;
begin
fillchar(distr, sizeof(distr), 0);
for i := 0 to Pred(n) do
inc(distr[source[i]]);
index[0] := 0;
for i := 1 to Pred(m) do
index[i] := index[Pred(i)] + distr[Pred(i)];
for i := 0 to Pred(n) do
begin
sorted[ index[source[i]] ] := source[i];
index[source[i]] := index[source[i]]+1;
end;
end;
var
b: arrType;
begin
RadixSort(a, b);
end.
Теория чисел.
Теория чисел является, возможно, самым интересным и красивым разделом математики. Доказательство Евклидом существования бесконечного количества простых чисел остается таким же четким и ясным сегодня, каким оно было более двух тысяч лет назад. Такие невинные вопросы, как существуют ли решения уравнения аn+bn=cn для целых a,b,c и n>2, часто оказывается совсем не такими невинными. Более того, это формулировка великой теоремы Ферма!
Компьютеры уже долгое время используют в исследованиях теории чисел. Проведение некоторых вычислений, связанных с теорией, для больших чисел требует значительной эффективности. К счастью, существует множество алгоритмов, которые могут помочь в этом.
Простые числа
Целое число р>1 называют простым, если оно делится только на 1 и на само себя. Говоря другими словами, если р – простое число, то равенство р=a*b для целых a≤b эквивалентно тому, что a=1 и b=p. Первые десять простых чисел: 2, 3, 5, 7,11, 13, 17, 19, 23 и 29.
Мы говорим, что число р является множителем числа х, если оно входит в его разложение на простые множители. Любое число не являющееся простым, называется составным.
Нахождение количества делителей и самих делители числа а.
Для этого будем перебирать все числа i, подходящие на роль делителя. Очевидно, что 1 <= i <= a. Чтобы ускорить работу алгоритма заметим, что если i – делитель а, то a/i – тоже делитель a, и к тому же одно из чисел i и a/i не превышает Sqrt(a) (если предположить противное, то получим a = i*(a/i) > Sqrt(a)*Sqrt(a) = a – противоречие). Поэтому достаточно перебирать числа i в пределах от 1 до Trunc(Sqrt(a)) и при нахождении, что некоторое i – делитель выдавать, что a/i – тоже делитель и увеличивать количество делителей на 2. Этот алгоритм не будет работать, когда a – точный квадрат, что легко исправляется.
Приведенные соображения реализованы в алгоритме (2):
c:= 0;
For i:= 1 to Trunc(Sqrt(a)) do
If a mod i = 0 then begin
If i*i = a then begin
c:= c+1;
WriteLn(‘Найден делитель ’, i);
end
else begin
c:= c+2;
if i=a div i then c:=c-1;
WriteLn(‘Найден делитель ‘, i);
WriteLn(‘Найден делитель ‘, a div i);
end;
end;
WriteLn(‘Количество делителей ‘, c);
Для того, чтобы проверить, является ли число простым, нужно посчитать количество его делителей, используя алгоритм 2.
Нахождение всех простых чисел, не превосходящих заданное число N.
Возможны несколько подходов к решению этой задачи:
1) Метод Эратосфена. Выпишем все числа от 2 до N. Затем, пока есть числа, которые не вычеркнуты и не обведены, делаем следующий набор операций: обводим минимальное из оставшихся чисел, вычеркиваем все числа, кратные ему. После окончания работы алгоритма все простые числа будут обведены.
Доказательство. Данный алгоритм не может вычеркнуть простое число, так как если число вычеркивается, то оно заведомо делится на какое-то другое, не равное ему. Теперь докажем по индукции, что для любого N алгоритм обводит все простые числа, не превосходящие N. База: при N = 2 утверждение верно, так как 2 будет обведено на 1-м шаге. Индуктивный переход: пусть утверждение верно при 2 <= N <= k-1. Рассмотрим N = k. Если N – составное, то у числа N есть простой делитель t, в качестве которого можно взять, например, его минимальный делитель (почему?). По индукции, на каком-то шаге число t будет обведено, на этом же шаге будет вычеркнуто N. Если же N – простое, то оно не может быть вычеркнуто, поэтому на каком-то шаге станет минимальным из оставшихся и будет обведено. Утверждение доказано.
Приведенные соображения реализованы в алгоритме:
FillChar(B, SizeOf(B), True);
For j:= 2 to N do
If B[j] then
Begin
WriteLn(j, ‘ – простое’);
i:= 2*j;
While i <= N do begin
B[i]:= False;
i:= i+j;
End;
end;
2) Будем хранить в массиве уже найденные простые числа. Рассматривая очередное число X, будем делить его на все уже полученные простые числа, не превосходящие Trunc(Sqrt(X)).
Доказательство. Корректность работы алгоритма следует из того, что, если число – составное, то оно обязательно имеет простой делитель, не превосходящий корня из этого числа.
Основная теорема алгебры.
Всякое число N представимо в виде произведения простых сомножителей, причем такое представление единственно с точностью до порядка сомножителей.
Доказательство. Для доказательства существования разложения воспользуемся индукцией по N с учетом, что любое число либо является простым, либо имеет простой делитель (проведите сами). Докажем единственность. Предположим, что N = p1p2…pk = t1t2…tl, где все сомножители – простые числа, причем p1<=…<=pk и t1<=…<=tl. С учетом соображений индукции, достаточно доказать, что p1 = t1 (почему?). Предположим противное и пусть, для определенности, p1 < t1. Так как t1, …, tl – простые, то p1 не является делителем каждого из этих чисел. Тем не менее p1 – делитель их произведения. Поэтому должны существовать числа a1, b1, …, al, bl такие, что a1b1 = t1, …, albl = tl, a1a2…ak = p1. Но, так как любое ai = 1 или ai = ti (ведь ti – простое число), то a1a2…ak либо равно 1, либо не меньше t1, что заведомо меньше, чем p1. Противоречие.
Из доказательства теоремы следует следующий алгоритм нахождения разложения числа на простые множители:
D:= 2;
While d <= Trunc(Sqrt(N)) do begin
While N mod d = 0 do begin
WriteLn(d);
N:= N div d;
end;
If d = 2 then d:= 3
else d:= d+2;
end;
If N <> 1 then WriteLn(N);
НОД и НОК
Если число c является делителем a и b, то говорят, что число c является общим делителем чисел a и b. Число d называют наибольшим общим делителем (НОД) чисел a и b, если d – общий делитель a и b и любой общий делитель a и b является делителем d.
Если числа a и b являются делителями числа c, то говорят, что число c является общим кратным чисел a и b. Число d называют наименьшим общим кратным (НОК) чисел a и b, если d – общее кратное a и b и d – делитель любого общего кратного a и b.
Если a =  , b =
, b =  , где ai, bi >= 0, то, очевидно, что НОД(a, b) =
, где ai, bi >= 0, то, очевидно, что НОД(a, b) =  и НОК(a, b) =
и НОК(a, b) =  . Отсюда, учитывая, что max{x,y}+min{x,y} = x+y, получаем ab = НОД(a, b)НОК(a, b).
. Отсюда, учитывая, что max{x,y}+min{x,y} = x+y, получаем ab = НОД(a, b)НОК(a, b).
Найдем НОД(a, b). Верны следующие равенства:
1) НОД(a, b) = НОД(b, a) – следует из определения.
2) НОД(a, 0) = a – очевидно.
3) НОД(a, b) = НОД(a mod b, b).
Доказательство. Докажем сначала, что НОД(a, b) = НОД(a-b, b). Пусть c – общий делитель a и b. Тогда a = kc, b = lc, a-b = (k-l)c, поэтому с – общий делитель a-b и b. Аналогично показывается, что если c – общий делитель (a-b) и b, то с – общий делитель a и b. Поэтому множества общих делителей пар (a, b) и (a-b, b) совпадают. А значит НОД(a,b) = НОД(a-b, b). Применяя эту формулу a div b раз, получим требуемое.
Для нахождения НОД можно использовать следующий алгоритм Евклида:
While (a<>0) and (b<>0) do
If a>b then a:= a mod b
else b:= b mod a;
nod:= a+b;
Корректность этого алгоритма следует из вышеуказанных свойств НОДа.
Справедливо следующее утверждение: существует целые числа u и v такие, что au+bv = НОД(a, b).
Доказательство. Находя НОД по алгоритму Евклида, мы, по сути дела, записали следующие равенства: a = q1b+r1, b = q2r1+r2, …, rn = qn+2rn+1+rn+2, rn+1 = qn+3rn+2. Причем НОД(a, b) = rn+2. Развернем эту цепочку равенств в другую сторону: НОД(a, b) = rn+2 = rn-qn+2rn+1 = rn-qn+2(rn-1-qn+1rn) = -qn+2rn-1+(1+qn+2qn+1)rn = krn-1+lrn = … = Ab+Br1 = Ab + B(a-q1b) = Ba + (A-Bq1)b = au + bv, что и требовалось доказать.
Из этого доказательства следует алгоритм нахождения u и v по a и b.
И в заключении рассмотрим задачу, предлагавшуюся на одной из олимпиад прошлых лет.
Красивые числа
Саша считает красивыми числа, десятичная запись которых не содержит других цифр, кроме 0 и k (1 ≤ k ≤ 9). Например, если k = 2, то такими числами будут 2, 20, 22, 2002 и т.п. Остальные числа Саше не нравятся, поэтому он представляет их в виде суммы красивых чисел. Например, если k = 3, то число 69 можно представить так: 69 = 33 + 30 + 3 + 3.
Однако, не любое натуральное число можно разложить в сумму красивых целых чисел. Например, при k = 5 число 6 нельзя представить в таком виде. Но если использовать красивые десятичные дроби, то это можно сделать: 6 = 5.5 + 0.5.
Недавно Саша изучил периодические десятичные дроби и начал использовать и их в качестве слагаемых. Например, если k = 3, то число 43 можно разложить так: 43 = 33.(3) + 3.(3) + 3 + 3.(3).
Оказывается, любое натуральное число можно представить в виде суммы положительных красивых чисел. Но такое разложение не единственно — например, число 69 можно также представить и как 69 = 33 + 33 + 3. Сашу заинтересовало, какое минимальное количество слагаемых требуется для представления числа n в виде суммы красивых чисел.
Требуется написать программу, которая для заданных чисел n и k находит разложение числа n в сумму положительных красивых чисел с минимальным количеством слагаемых.
Формат входных данных
Во входном файле записаны два натуральных числа n и k (1 ≤ n ≤ 109; 1≤ k ≤ 9).
Формат выходных данных
В выходной файл выведите разложение числа n в сумму положительных чисел, содержащих только цифры 0 и k, количество слагаемых в котором минимально. Разложение должно быть представлено в виде:
n=a1+a2+...+am
Слагаемые a1, a2, ..., am должны быть выведены без ведущих нулей, без лишних нулей в конце дробной части. Запись каждого слагаемого должна быть такой, что длины периода и предпериода дробной части имеют минимально возможную длину. Например, неправильно выведены числа: 07.7; 2.20; 55.5(5); 0.(66); 7.(0); 7. ; .5; 0.33(03). Их следует выводить так: 7.7; 2.2; 55.(5); 0.(6); 7; 7; 0.5; 0.3(30).
Предпериод и период каждого из выведенных чисел должны состоять не более чем из 100 цифр. Гарантируется, что хотя бы одно такое решение существует. Если искомых решений несколько, выведите любое. Порядок слагаемых может быть произвольным.
Выходной файл не должен содержать пробелов.
Примеры
n = a1 + a2 + ... + am,
где каждый ai состоит только из цифр 0 и k.
Разделим обе части на k. Понятно, что при этом в числах ai все цифры k заменятся на единицы, а нули останутся нулями.
Получается новая формулировка задачи: представить число n / k как сумму чисел, состоящих только из цифр 0 и 1. Утверждается, что ответ на нее таков: минимальное количество слагаемых равно максимальной цифре в десятичной записи числа n / k.
Докажем сначала, что меньшим числом слагаемых обойтись нельзя. Будем действовать от противного: предположим, что можно обойтись меньшим числом слагаемых. При этом, так как максимальная цифра в n / k не превышает 9, то мы предполагаем, что можно обойтись не более чем восемью слагаемыми. Выпишем эти слагаемые друг под другом (даже если они бесконечные) и сложим «в столбик». При этом переносов не будет (все цифры 0 или 1, и цифр в каждом столбце не больше 8). Рассмотрим тот столбец, в котором при суммировании должна получиться максимальная цифра из десятичной записи n / k. Даже если во всех слагаемых в этом столбце стоят единицы, все равно нужная сумма не набирается. Получили противоречие; утверждение доказано.
Теперь, пожалуй, понятно, как добиться описанного выше ответа: надо просто в каждом столбце расставить столько единиц, сколько нужно получить в сумме – это соответствующая цифра из n / k.
Пример. Пусть n = 15, k = 7.
15/7 = 2,(142857)
Максимальная цифра — 8. Подберем соответствующие восемь слагаемых.
1,(111111)
1,(011111)
0,(010111)
0,(010111)
0,(000111) +
0,(000101)
0,(000101)
0,(000100)
----------
2,(142857)
Теперь умножим эти числа на 7, и получим следующее верное равенство:
15 = 7,(7) + 7,(077777) + 0,(070777) + 0,(070777) + 0,(000777) + 0,(000707) + 0,(000707) + 0,(000700)
Таким образом, правильное решение состоит из следующих этапов: представление числа n / k в удобном для обработки формате (с аккуратным учетом периода), составление искомых слагаемых и их вывод с учетом имеющихся требований.
Список используемой литературы:
1. Стивен С. Скиена, Мигель А. Ревилла Олимпиадные задачи по программированию, Москва Кудиц-Образ, 2005
2. Немнюгин С.А. Turbo Pascal, издательский дом «Питер», 2004
Простые числа
Целое число р>1 называют простым, если оно делится только на 1 и на само себя. Говоря другими словами, если р – простое число, то равенство р=a*b для целых a≤b эквивалентно тому, что a=1 и b=p. Первые десять простых чисел: 2, 3, 5, 7,11, 13, 17, 19, 23 и 29.
Мы говорим, что число р является множителем числа х, если оно входит в его разложение на простые множители. Любое число не являющееся простым, называется составным.
Нахождение количества делителей и самих делители числа а.
Для этого будем перебирать все числа i, подходящие на роль делителя. Очевидно, что 1 <= i <= a. Чтобы ускорить работу алгоритма заметим, что если i – делитель а, то a/i – тоже делитель a, и к тому же одно из чисел i и a/i не превышает Sqrt(a) (если предположить противное, то получим a = i*(a/i) > Sqrt(a)*Sqrt(a) = a – противоречие). Поэтому достаточно перебирать числа i в пределах от 1 до Trunc(Sqrt(a)) и при нахождении, что некоторое i – делитель выдавать, что a/i – тоже делитель и увеличивать количество делителей на 2. Этот алгоритм не будет работать, когда a – точный квадрат, что легко исправляется.
Приведенные соображения реализованы в алгоритме (2):
c:= 0;
For i:= 1 to Trunc(Sqrt(a)) do
If a mod i = 0 then begin
If i*i = a then begin
c:= c+1;
WriteLn(‘Найден делитель ’, i);
end
else begin
c:= c+2;
if i=a div i then c:=c-1;
WriteLn(‘Найден делитель ‘, i);
WriteLn(‘Найден делитель ‘, a div i);
end;
end;
WriteLn(‘Количество делителей ‘, c);
Для того, чтобы проверить, является ли число простым, нужно посчитать количество его делителей, используя алгоритм 2.
Нахождение всех простых чисел, не превосходящих заданное число N.
Возможны несколько подходов к решению этой задачи:
1) Метод Эратосфена. Выпишем все числа от 2 до N. Затем, пока есть числа, которые не вычеркнуты и не обведены, делаем следующий набор операций: обводим минимальное из оставшихся чисел, вычеркиваем все числа, кратные ему. После окончания работы алгоритма все простые числа будут обведены.
Доказательство. Данный алгоритм не может вычеркнуть простое число, так как если число вычеркивается, то оно заведомо делится на какое-то другое, не равное ему. Теперь докажем по индукции, что для любого N алгоритм обводит все простые числа, не превосходящие N. База: при N = 2 утверждение верно, так как 2 будет обведено на 1-м шаге. Индуктивный переход: пусть утверждение верно при 2 <= N <= k-1. Рассмотрим N = k. Если N – составное, то у числа N есть простой делитель t, в качестве которого можно взять, например, его минимальный делитель (почему?). По индукции, на каком-то шаге число t будет обведено, на этом же шаге будет вычеркнуто N. Если же N – простое, то оно не может быть вычеркнуто, поэтому на каком-то шаге станет минимальным из оставшихся и будет обведено. Утверждение доказано.
Приведенные соображения реализованы в алгоритме:
FillChar(B, SizeOf(B), True);
For j:= 2 to N do
If B[j] then
Begin
WriteLn(j, ‘ – простое’);
i:= 2*j;
While i <= N do begin
B[i]:= False;
i:= i+j;
End;
end;
2) Будем хранить в массиве уже найденные простые числа. Рассматривая очередное число X, будем делить его на все уже полученные простые числа, не превосходящие Trunc(Sqrt(X)).
Доказательство. Корректность работы алгоритма следует из того, что, если число – составное, то оно обязательно имеет простой делитель, не превосходящий корня из этого числа.
Основная теорема алгебры.
Всякое число N представимо в виде произведения простых сомножителей, причем такое представление единственно с точностью до порядка сомножителей.
Доказательство. Для доказательства существования разложения воспользуемся индукцией по N с учетом, что любое число либо является простым, либо имеет простой делитель (проведите сами). Докажем единственность. Предположим, что N = p1p2…pk = t1t2…tl, где все сомножители – простые числа, причем p1<=…<=pk и t1<=…<=tl. С учетом соображений индукции, достаточно доказать, что p1 = t1 (почему?). Предположим противное и пусть, для определенности, p1 < t1. Так как t1, …, tl – простые, то p1 не является делителем каждого из этих чисел. Тем не менее p1 – делитель их произведения. Поэтому должны существовать числа a1, b1, …, al, bl такие, что a1b1 = t1, …, albl = tl, a1a2…ak = p1. Но, так как любое ai = 1 или ai = ti (ведь ti – простое число), то a1a2…ak либо равно 1, либо не меньше t1, что заведомо меньше, чем p1. Противоречие.
Из доказательства теоремы следует следующий алгоритм нахождения разложения числа на простые множители:
D:= 2;
While d <= Trunc(Sqrt(N)) do begin
While N mod d = 0 do begin
WriteLn(d);
N:= N div d;
end;
If d = 2 then d:= 3
else d:= d+2;
end;
If N <> 1 then WriteLn(N);
НОД и НОК
Если число c является делителем a и b, то говорят, что число c является общим делителем чисел a и b. Число d называют наибольшим общим делителем (НОД) чисел a и b, если d – общий делитель a и b и любой общий делитель a и b является делителем d.
Если числа a и b являются делителями числа c, то говорят, что число c является общим кратным чисел a и b. Число d называют наименьшим общим кратным (НОК) чисел a и b, если d – общее кратное a и b и d – делитель любого общего кратного a и b.
Если a =
Найдем НОД(a, b). Верны следующие равенства:
1) НОД(a, b) = НОД(b, a) – следует из определения.
2) НОД(a, 0) = a – очевидно.
3) НОД(a, b) = НОД(a mod b, b).
Доказательство. Докажем сначала, что НОД(a, b) = НОД(a-b, b). Пусть c – общий делитель a и b. Тогда a = kc, b = lc, a-b = (k-l)c, поэтому с – общий делитель a-b и b. Аналогично показывается, что если c – общий делитель (a-b) и b, то с – общий делитель a и b. Поэтому множества общих делителей пар (a, b) и (a-b, b) совпадают. А значит НОД(a,b) = НОД(a-b, b). Применяя эту формулу a div b раз, получим требуемое.
Для нахождения НОД можно использовать следующий алгоритм Евклида:
While (a<>0) and (b<>0) do
If a>b then a:= a mod b
else b:= b mod a;
nod:= a+b;
Корректность этого алгоритма следует из вышеуказанных свойств НОДа.
Справедливо следующее утверждение: существует целые числа u и v такие, что au+bv = НОД(a, b).
Доказательство. Находя НОД по алгоритму Евклида, мы, по сути дела, записали следующие равенства: a = q1b+r1, b = q2r1+r2, …, rn = qn+2rn+1+rn+2, rn+1 = qn+3rn+2. Причем НОД(a, b) = rn+2. Развернем эту цепочку равенств в другую сторону: НОД(a, b) = rn+2 = rn-qn+2rn+1 = rn-qn+2(rn-1-qn+1rn) = -qn+2rn-1+(1+qn+2qn+1)rn = krn-1+lrn = … = Ab+Br1 = Ab + B(a-q1b) = Ba + (A-Bq1)b = au + bv, что и требовалось доказать.
Из этого доказательства следует алгоритм нахождения u и v по a и b.
И в заключении рассмотрим задачу, предлагавшуюся на одной из олимпиад прошлых лет.
Красивые числа
| Имя входного файла: | numbers.in |
| Имя выходного файла: | numbers.out |
| Максимальное время работы на одном тесте: | 1 секунда |
| Максимальный объем используемой памяти: | 64 мегабайта |
Однако, не любое натуральное число можно разложить в сумму красивых целых чисел. Например, при k = 5 число 6 нельзя представить в таком виде. Но если использовать красивые десятичные дроби, то это можно сделать: 6 = 5.5 + 0.5.
Недавно Саша изучил периодические десятичные дроби и начал использовать и их в качестве слагаемых. Например, если k = 3, то число 43 можно разложить так: 43 = 33.(3) + 3.(3) + 3 + 3.(3).
Оказывается, любое натуральное число можно представить в виде суммы положительных красивых чисел. Но такое разложение не единственно — например, число 69 можно также представить и как 69 = 33 + 33 + 3. Сашу заинтересовало, какое минимальное количество слагаемых требуется для представления числа n в виде суммы красивых чисел.
Требуется написать программу, которая для заданных чисел n и k находит разложение числа n в сумму положительных красивых чисел с минимальным количеством слагаемых.
Формат входных данных
Во входном файле записаны два натуральных числа n и k (1 ≤ n ≤ 109; 1≤ k ≤ 9).
Формат выходных данных
В выходной файл выведите разложение числа n в сумму положительных чисел, содержащих только цифры 0 и k, количество слагаемых в котором минимально. Разложение должно быть представлено в виде:
n=a1+a2+...+am
Слагаемые a1, a2, ..., am должны быть выведены без ведущих нулей, без лишних нулей в конце дробной части. Запись каждого слагаемого должна быть такой, что длины периода и предпериода дробной части имеют минимально возможную длину. Например, неправильно выведены числа: 07.7; 2.20; 55.5(5); 0.(66); 7.(0); 7. ; .5; 0.33(03). Их следует выводить так: 7.7; 2.2; 55.(5); 0.(6); 7; 7; 0.5; 0.3(30).
Предпериод и период каждого из выведенных чисел должны состоять не более чем из 100 цифр. Гарантируется, что хотя бы одно такое решение существует. Если искомых решений несколько, выведите любое. Порядок слагаемых может быть произвольным.
Выходной файл не должен содержать пробелов.
Примеры
| numbers.in | numbers.out |
| 69 3 | 69=33+33+3 |
| 6 5 | 6=5.5+0.5 |
| 10 9 | 10=9.(9) |
Разбор задачи «Красивые числа»
Рассмотрим искомое равенство:n = a1 + a2 + ... + am,
где каждый ai состоит только из цифр 0 и k.
Разделим обе части на k. Понятно, что при этом в числах ai все цифры k заменятся на единицы, а нули останутся нулями.
Получается новая формулировка задачи: представить число n / k как сумму чисел, состоящих только из цифр 0 и 1. Утверждается, что ответ на нее таков: минимальное количество слагаемых равно максимальной цифре в десятичной записи числа n / k.
Докажем сначала, что меньшим числом слагаемых обойтись нельзя. Будем действовать от противного: предположим, что можно обойтись меньшим числом слагаемых. При этом, так как максимальная цифра в n / k не превышает 9, то мы предполагаем, что можно обойтись не более чем восемью слагаемыми. Выпишем эти слагаемые друг под другом (даже если они бесконечные) и сложим «в столбик». При этом переносов не будет (все цифры 0 или 1, и цифр в каждом столбце не больше 8). Рассмотрим тот столбец, в котором при суммировании должна получиться максимальная цифра из десятичной записи n / k. Даже если во всех слагаемых в этом столбце стоят единицы, все равно нужная сумма не набирается. Получили противоречие; утверждение доказано.
Теперь, пожалуй, понятно, как добиться описанного выше ответа: надо просто в каждом столбце расставить столько единиц, сколько нужно получить в сумме – это соответствующая цифра из n / k.
Пример. Пусть n = 15, k = 7.
15/7 = 2,(142857)
Максимальная цифра — 8. Подберем соответствующие восемь слагаемых.
1,(111111)
1,(011111)
0,(010111)
0,(010111)
0,(000111) +
0,(000101)
0,(000101)
0,(000100)
----------
2,(142857)
Теперь умножим эти числа на 7, и получим следующее верное равенство:
15 = 7,(7) + 7,(077777) + 0,(070777) + 0,(070777) + 0,(000777) + 0,(000707) + 0,(000707) + 0,(000700)
Таким образом, правильное решение состоит из следующих этапов: представление числа n / k в удобном для обработки формате (с аккуратным учетом периода), составление искомых слагаемых и их вывод с учетом имеющихся требований.
Список используемой литературы:
1. Стивен С. Скиена, Мигель А. Ревилла Олимпиадные задачи по программированию, Москва Кудиц-Образ, 2005
2. Немнюгин С.А. Turbo Pascal, издательский дом «Питер», 2004